日期:2026年 06月 27日
標籤: Linux Ubuntu Docker Docker-Compose Container Stable Diffusion ComfyUI WSL 2 Wan 2.1 LoRA
摘要:生成式AI
應用所需:1. 已安裝 Windows 的 Docker Desktop (Use WSL 2 instead of Hyper-V)
2. 已安裝 Hyper-V + ComfyUI(容器化)
3. 顯示卡使用 RTX 5070 以上 + 12G VRAM
4. Windows 10 以上作業系統
解決問題:1. 延續上一篇文章,並且當顯示卡低於 16 VRAM 的優化 Wan 2.1 生成影片的優化方案
2. 使用 LightX2V LoRA 模型進行加速,並且保持品質,並說明 LightX2V (Low_Noise) 為何可提高效能
相關參考:0002. ComfyUI容器化執行 Wan 2.1(2.2) 生成影片(圖片生成影片) + 頻頻跳出 Killed 錯誤? 說明隱藏在 Windowss 下 WSL2 記憶體限制裡的 OOM 隱形殺手
2. Wan-AI Github
基本介紹:本篇分為三大部分。
第一部分:問題描述
第二部分:優化工作流-導入 Lora 模型
第三部分:驗證成果
第一部分:問題描述
Step 1:Wan 2.1(2.2) 執行效能慢補充
若受限於顯示卡 VRAM 不足於 16G 的情況下,用一般的方式執行 Wan 2.1(2.2) 圖片生成影片效能會很差,因為 VRAM 不足的情況下會導致
不斷把資料「往系統 RAM 甚至硬碟 Swap 搬運 (Offload)」
因此上一篇生成 5 秒的影片,25 分鐘有很多都是在執行釋放記憶體的工作
Step 2:本篇說明 - 對應規格
若硬體設備遠高於此,基本上 VRAM 不足的問題應不容易發生,可不用檢閱此篇內容
| 項目 | 規格 |
|---|---|
| GPU | 名稱 NVIDIA GeForce RTX 5070 (12G VRAM) |
| CPU | Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz,3192 Mhz,6 個核心,12 個邏輯處理器 |
| RAM | 48 GB |
| OS | Microsoft Windows 10 專業版 |
第二部分:優化工作流-導入 Lora 模型
Step 1:問題本質
LightX2V 屬於蒸餾模型,強迫 4 步版本的輸出去模仿 20 步的結果
在 Wan 2.1(2.2) 的原始模型中,使用了 Step 20 步,AI 影片生成的過程,本質上是 去噪(Denoising)
純雜訊 → → → → → → → → → → 清晰影片
Step1 Step5 Step10 Step20
因此 Wan Wan 2.1(2.2) 的 K 採樣器 在步數中預設 20 ,當往下調整時,效能會明顯提升,但產出的影片品質也明顯下降
Step 2:解決方案 - 使用 LightX2V LoRA
LightX2V 屬於蒸餾模型,簡言之 : 強迫 4 步版本的輸出去模仿 20 步的結果
而 LoRA(Low-Rank Adaptation)是一種微調技術,不修改原始模型的權重,而是在旁邊添加「修正層」,核心概念就是知識蒸餾(Knowledge Distillation)
Teacher Model(20步,高品質)
↓ 教學
Student Model(4步,學習如何一步頂五步)
↓ 產出
LightX2V LoRA 權重
LightX2V 的 Loar 訓練過程:
| 1. 用原始 20 步模型生成大量高品質影片作為「標準答案」 |
| 2. 強迫 4 步版本的輸出去模仿 20 步的結果 |
| 3. 把「如何用 4 步達到 20 步品質」的知識,壓縮進 LoRA 權重中 |
Step 3:LightX2V LoRA 與原始模型差異
與原始的 4 步相比較, LightX2V 的 4 步原理差異如下 :
| 步數 | 一般 4 步(無 LoRA) | LightX2V 4 步(有 LoRA) |
|---|---|---|
| 1. | 粗略去噪 | 已學會「大跨步去噪」的方式 |
| 2. | 輪廓模糊 | 快速建立正確結構 |
| 3. | 細節不足 | 補充關鍵細節 |
| 4. | 品質差 | 達到接近 20 步的品質 |
整體流程對比,得到的結果: 速度快 5 倍,品質幾乎相同。
【一般 20 步】
雜訊 →(小步)→(小步)→(小步)→... 20次 ...→ 影片
每步 CFG=6 大力糾正方向
【LightX2V 4 步】
雜訊 →(大步,已學過)→(大步,已學過)→(大步)→(大步)→ 影片
每步 CFG=1 信任模型自己的判斷
Step 4:LightX2V LoRA 缺點 & 應用場景
任何技術實際上都有取捨, LightX2V LoRA 具有以下缺點 :
| 1. 創意自由度降低 | 步數極少,模型走的是「最有把握的路」 |
| 2. 複雜動作表現較差 | 在複雜動作(舞蹈、打鬥)、多人互動會出現模糊、混亂的表現 |
| 3. 對 Prompt 的理解能力下降 | 蒸餾模型學的是「快速到達好結果」,而不是「深度理解 Prompt」,4步 LoRA 可能只抓到關鍵字 |
| 4. 必須把 CFG 設成 1.0,完全失去 CFG 的調控能力 | CFG 高 → 更貼近 Prompt ; Lora 4 步只能用 CFG=1.0,無法調整這個維度 |
| 5. 與其他 LoRA 疊加相容性差 | 正常模型可同時疊加多個 Lora 模型(風格 LoRA + 角色 LoRA),但 4 步Lora 容易異常跟品質下降 |
這也說明了 為何 Wan 預設不使用 LightX2V
| 原因 | 說明 |
|---|---|
| 1. 品質優先 | 原始模型是品質基準,官方不想預設犧牲任何品質 |
| 2. 靈活性 | 使用者可能有不同需求,速度或品質各有偏好 |
| 3. 授權分離 | LightX2V 是第三方社群訓練,不是 Wan 官方出品 |
| 4. 適用場景不同 | 專業用途需要最高品質,速度不是首要考量 |
結論: 什麼時候用 LightX2V 4步 LoRA
用 LightX2V 4步 LoRA:
✅ 快速測試 Prompt 效果
✅ 簡單動作、單人場景
✅ 大量批次生成
✅ 個人創作、快速迭代
用原始 20步(無 LoRA):
✅ 最終輸出、追求最高品質
✅ 複雜動作、多人場景
✅ 需要精確控制 Prompt 細節
✅ 商業用途
實務上即使高階顯卡,通常先用 4步 LoRA 快速測試,確認構圖、動作、場景都滿意後,再轉回用 20步 做最終高品質輸出。
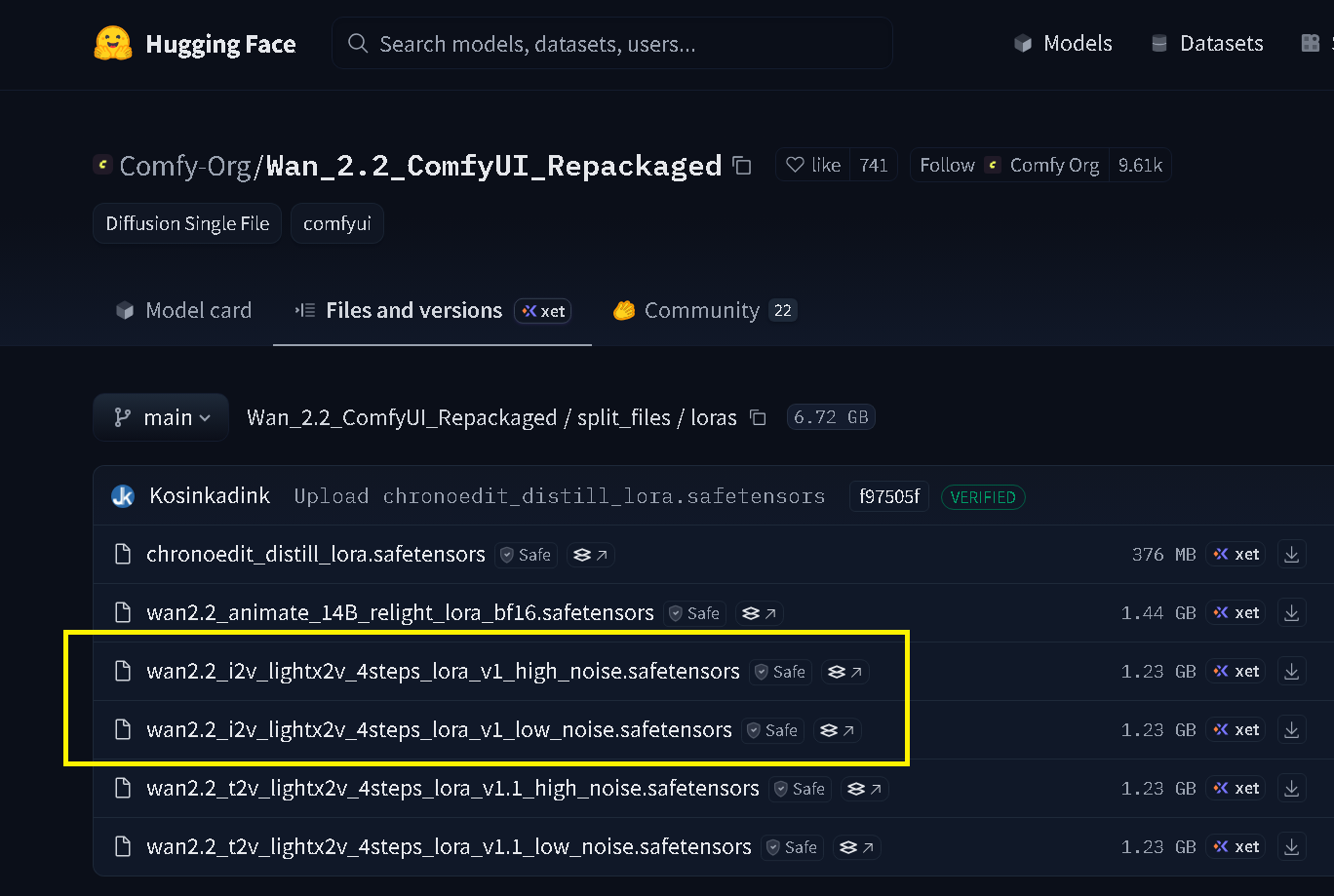
Step 5:導入 4步 Lora - 下載模型
進入下載模型Comfy-Org 官方重新打包的版本,如下圖
| 項目 | High Noise | Low Noise |
|---|---|---|
| 適合場景 | 動態大、運動幅度明顯的影片 | 細節豐富、靜態或輕微動作的影片 |
| 畫面風格 | 對應原 high_noise_14B 主模型 | 對應原 low_noise_14B 主模型 |
| 搭配原則 | 必須配 high noise 主模型使用 | 必須配 low noise 主模型使用 |
注意:High/Low LoRA 必須與對應的主模型搭配,不能交叉使用!否則容易出現異常影片
Step 6:導入 4步 Lora - 放到正確位置
下載完成後,放到對應目錄,可以參考圖示:
ComfyUI/
└── models/
└── loras/
├── wan2.2_i2v_lightx2v_4steps_lora_v1_high_noise.safetensors ← high_noise 放這裡
└── wan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensors ← low_noise 放這裡
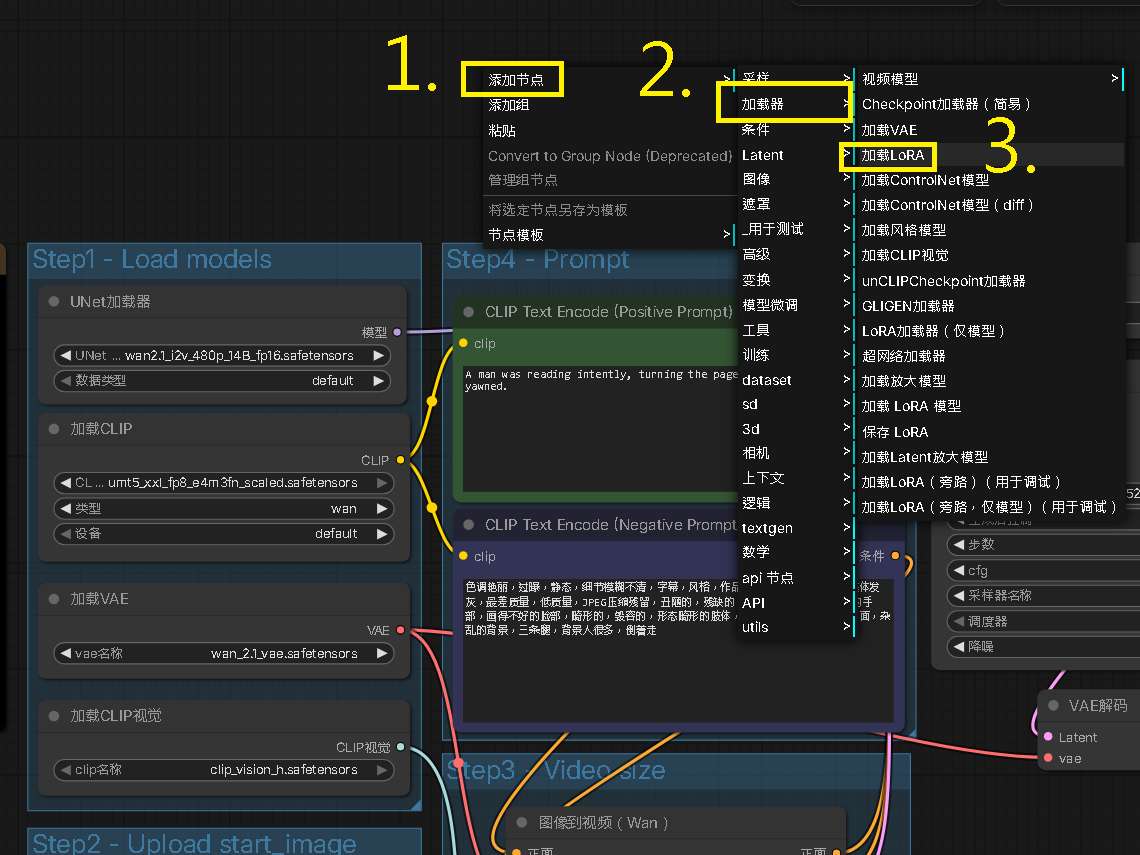
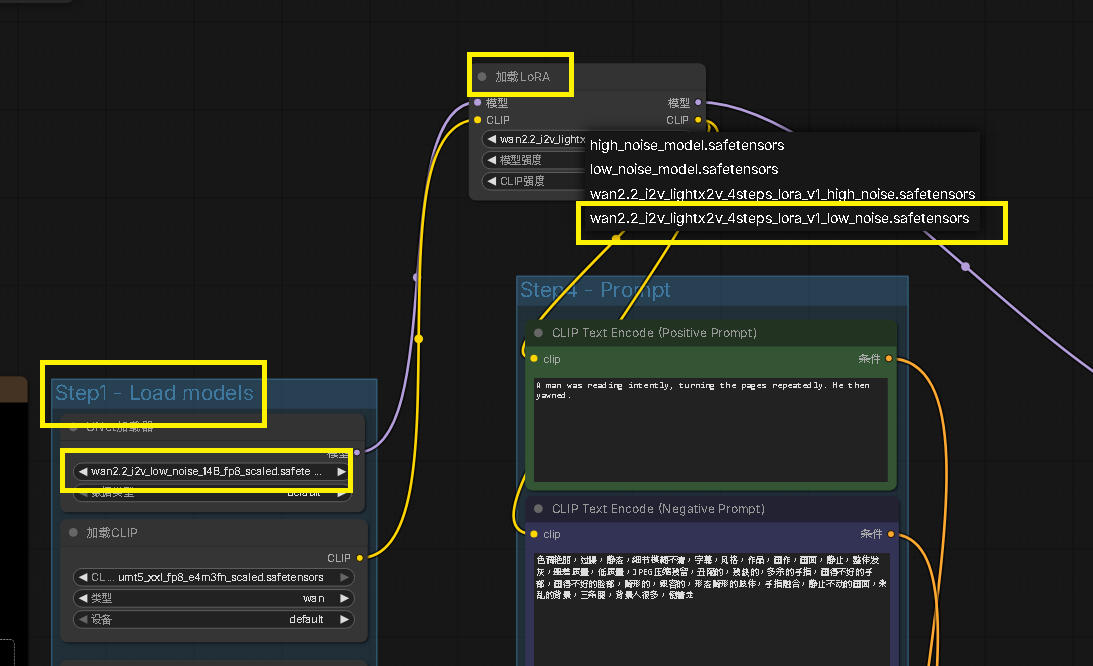
Step 7:導入 4步 Lora - 調整 ComfyUI 工作流
上一篇文章的工作流步驟如下:
UNet加載器
└─ 模型 ──→ 模型 ──→ K采樣器
加載CLIP
└─ CLIP ──→ CLIP ──→ CLIP Text Encode
我們目標是添加 Lora 模型
UNet加載器
└─ 模型 ──→ Load LoRA ──→ 模型 ──→ K采樣器
加載CLIP
└─ CLIP ──→ Load LoRA ──→ CLIP ──→ CLIP Text Encode
因此先在 ComfyUI 空白處,添加 Lora 加載器
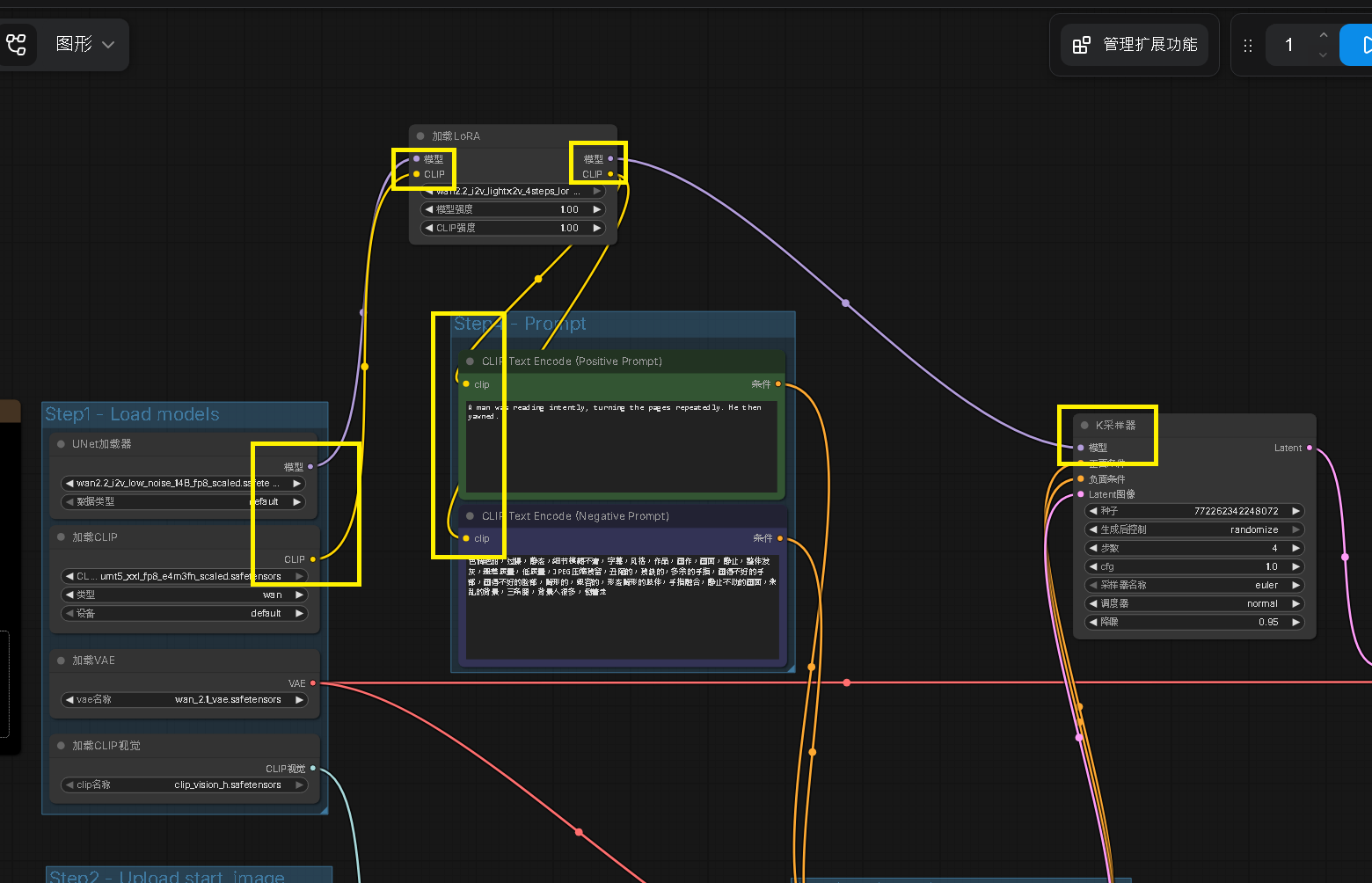
Step 8:導入 4步 Lora - 調整 ComfyUI Lora加載器節點
接著如下圖將 Loar 加載器的輸入、輸出,節點調整
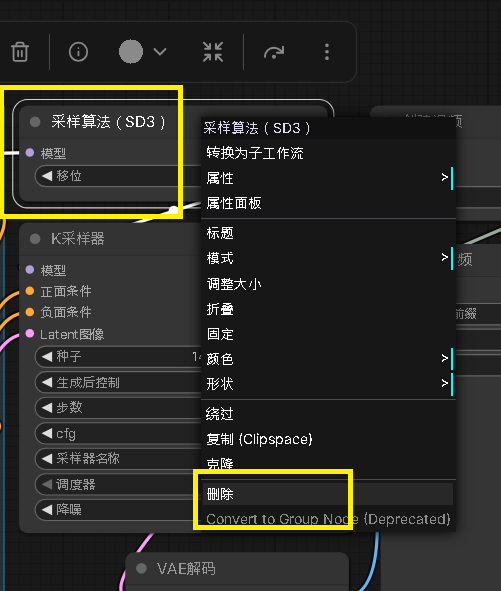
Step 9:導入 4步 Lora - 必須移除採樣算法SD3
上一篇文章中,原始的 Wan 模型會需要採樣算法SD3(Stable Diffusion 3),但是這是 Lora 模型因此不需要
因此若不移除會造成生成錯誤或品質下降
加載LoRA ──模型──→ K采樣器(直接連接,不經過SD3)
Step 10:導入 4步 Lora - 主模型、Lora模型設定
可以依照自己的 prompt 與影片目的選擇 high / low 版本,這邊使用 low 版本,要呈現一個看書的人打哈欠的影片
主模型:wan2.2_i2v_low_noise_14B_fp8_scaled.safetensors
Loar模型:wan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensors
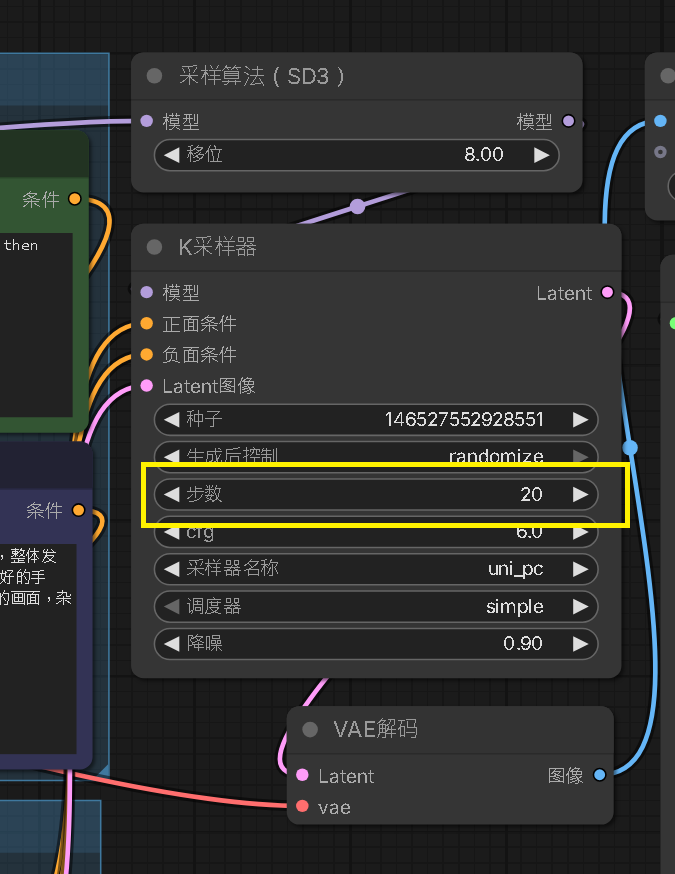
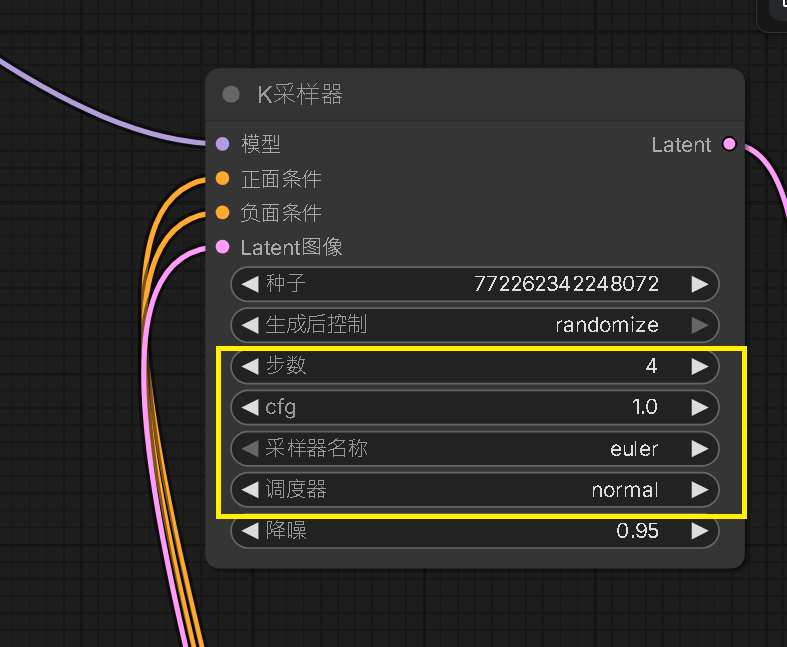
Step 11:導入 4步 Lora - K採樣器參數調整
依照 ComfyUI 版本不同,會出現的參數可能也不盡相同,但以下是需要對應 Lora Model 調整:
| 步數 | 4 | 必須引為 lightx2v 適合 4 步 |
| CFG | 1.0 | 必須符合 |
| 採樣器名稱 | eular | 折衷方案,flow_dpm 為最佳 |
| 調度器 | normal | 折衷方案,simple_linear 為最佳 |
以下是 採樣器名稱 參考列表
| 優先順序 | 採樣器名稱 | 說明 |
|---|---|---|
| 1. | flow_dpm | 最佳,專為 Flow 模型設計 |
| 2. | simple_linear | 次佳替代,適合少步數 |
| 3. | linear | 可用 |
| 4. | euler | 通用,穩定 |
| 5. | simple | 少步數效果較差 |
第三部分:驗證成果
Step 1:開始執行 ITV - DEMO結果
最後嘗試執行,我們平均花費約 4~7 分鐘間完成生成 5 秒影片,並且影片品質能保持一定水準(如前所述,不能太複雜)
生成結果 - Youtube 播放:
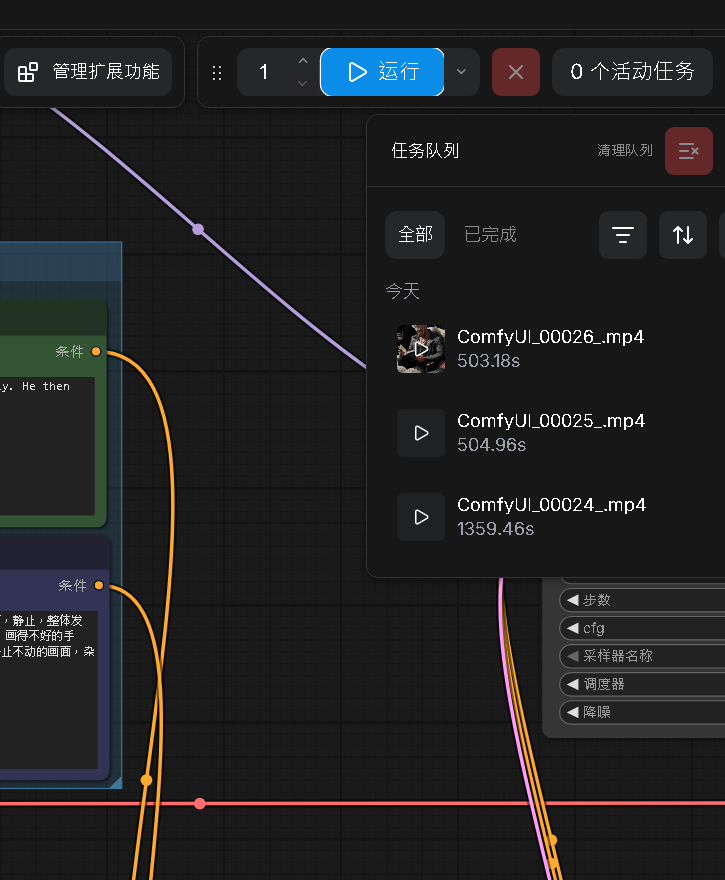
Step 2:補充說明,首次執行狀況
補充:因為本身電腦硬體規格的關係,若 VRAM 較差(本篇12G) 首次執行通常會比較慢
第一次執行:模型需要從硬碟載入到 VRAM → 慢
第二次執行:模型已在 VRAM 快取中 → 快
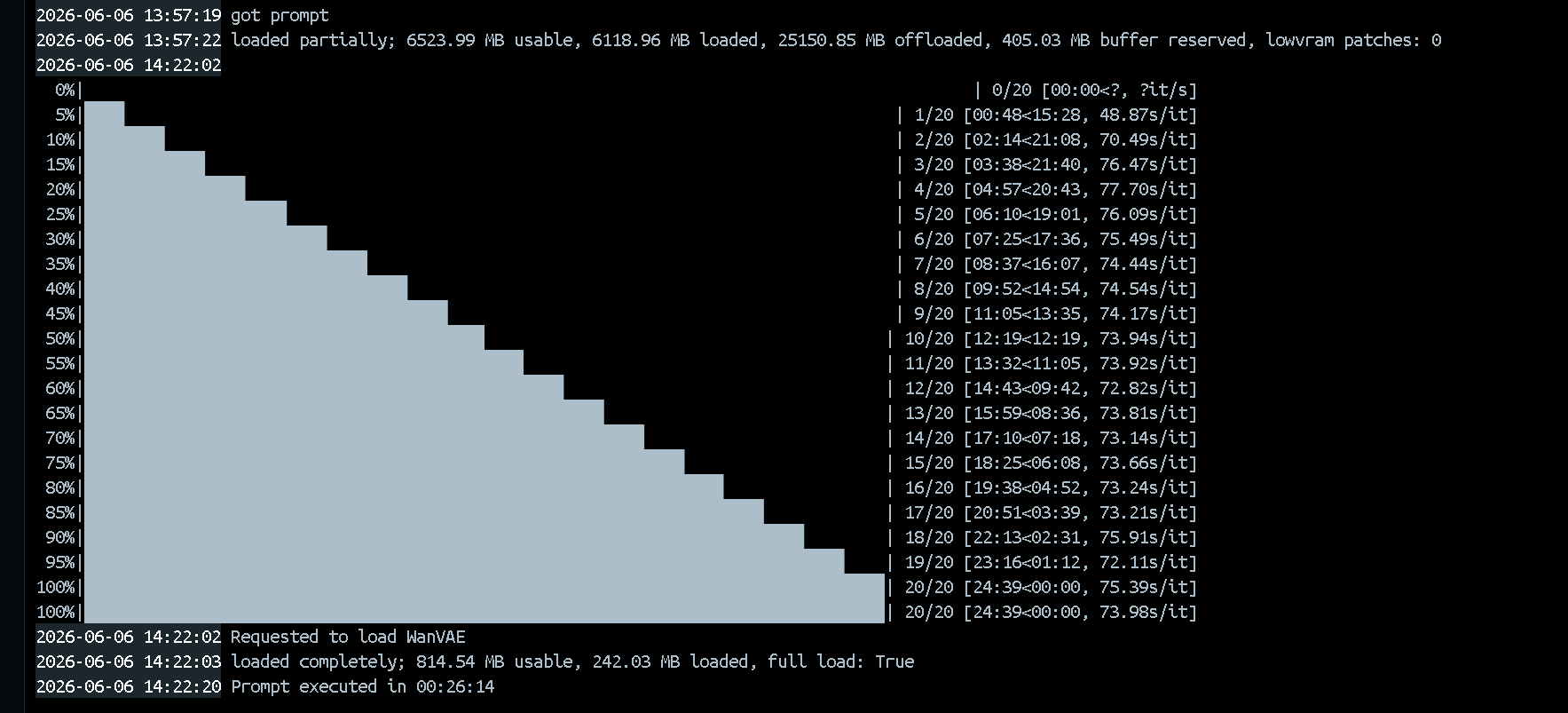
可以觀察到第一次執行花費 1359.46 秒,約 20 分鐘,但第 2 次之後,都壓縮到 500 秒左右
若將本機電腦的一些常駐軟體關閉後,在多次執行(後續執行約 30 次),可以觀察到約 150秒 ~ 300 秒之間
對於 12G VRAM 的顯卡都是一個很卓越的執行效能提升