日期:2026年 06月 20日
標籤: Linux Ubuntu Docker Docker-Compose Container Stable Diffusion ComfyUI WSL 2
摘要:生成式AI
應用所需:1. 已安裝 Windows 的 Docker Desktop (Use WSL 2 instead of Hyper-V)
2. 已安裝 Hyper-V + ComfyUI(容器化)
3. 顯示卡使用 RTX 5070 以上 + 12G VRAM
4. Windows 10 以上作業系統
解決問題:1. 如何快速本地化搭建 ComfyUI Wan 2.1 (含2.2,方法相同)
2. 解決 comfyui-nvidia_init.bash: line 935: 308 Killed 記憶體不足問題
相關參考:0001. 2026 最新|RTX 5070 + Docker + ComfyUI 完整安裝教學(Windows WSL2_)
2. Wan-AI Github
基本介紹:本篇分為三大部分。
第一部分:本地化運行 WAN 2.1
第二部分:遭遇問題 & 解決方法
第三部分:遺留問題
第一部分:本地化運行 WAN 2.1
Step 1:Wan2.1 介紹
Wan 2.1 有以下介紹,是 AI影片生成模型
| 1. | Wan 2.1 是阿里巴巴於 2025 年 2 月正式發布的開源 AI 影片生成模型,採用 Apache 2.0 授權,全球開發者和企業可免費使用,無任何限制。 |
| 2. | Wan 2.1 系列模型在 Hugging Face 和 ModelScope 上已累積超過 220 萬次下載,並在 VBench(影片生成模型綜合評測榜單)中位居榜首。 |
Wan 2.1 系列包含了四種模型,參數量從 13 億到 140 億不等
| 1. | T2V-14B | 文字生成影片 |
| 2. | T2V-1.3B | 文字生成影片 |
| 3. | I2V-14B-720P | 圖片生成影片 |
| 4. | I2V-14B-480P | 圖片生成影片 |
基本上 WAN 2.1 AI生成影片,有較多的社群資源與使用者,相關異常都能很快速地找出,並且也仍在持續更新,2026/6/7 已經到 WAN 2.2
Step 2:Wan2.1 功能總覽
Wan 2.1 的AI模型並且以擴展出以下的應用,若有相關的需求可以進一步導入
| 功能 | 說明 |
|---|---|
| 1. T2V 文字生影片 | 輸入文字描述,生成連貫的影片 |
| 2. I2V 圖片生影片 | 將靜態圖片動畫化,支援最高 720p |
| 3. 視頻編輯 | 透過文字或圖片參考對現有影片精確編輯 |
| 4. T2I 文字生圖片 | 直接從文字提示生成圖片 |
| 5. V2A 影片生音訊 | 為影片生成對應的音軌 |
Step 3:Wan 優點、缺點
Wan 2.1 的AI模型並且以擴展出以下的應用,若有相關的需求可以進一步導入
| 面相 | 優點 | 缺點 |
|---|---|---|
| 開源授權 | Apache 2.0,完全免費商用 | |
| 硬體需求 | 1.3B 小模型只需 8.19GB VRAM,幾乎相容所有消費級顯示卡 | 14B 模型需要 12GB+ VRAM |
| 影片品質 | 可生成大幅度動作、高保真度、細節逼真的影片 | 長影片一致性仍有挑戰 |
| 語言支援 | 全球首個可在影片中同時生成中英文文字的影片模型 | |
| 生態整合 | 發布隔天即整合進 ComfyUI,之後也整合進 Diffusers 函式庫 | |
| VAE 能力 | Wan-VAE 可對任意長度的 1080P 影片進行編解碼,同時保留時序資 | |
| 生成速度 | 1.3B 速度快;搭配 LightX2V 可大幅加速 | 14B 無優化下生成速度慢 |
| 社群資源 | 社群活躍,GGUF/LoRA 資源豐富 | Wan 2.2 的 GGUF 資源相對較少 |
簡言之,很適合用來進行AI生成影片
Step 4:導入模型
目前有現成主流的模板,很適合直接快速上手,如下開啟 ComfyUI 後依序選擇
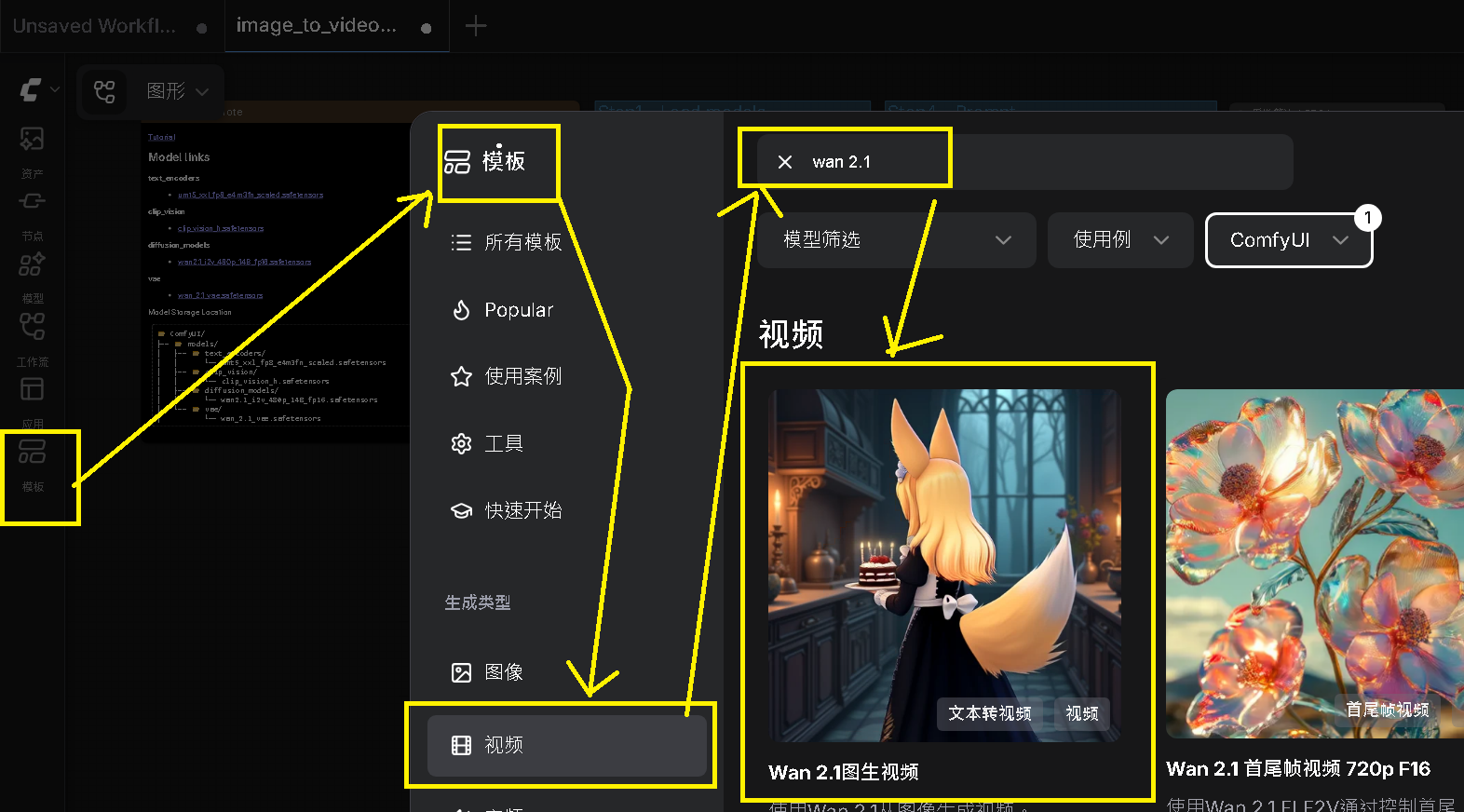
Step 5:導入模型 - 下載對應模型
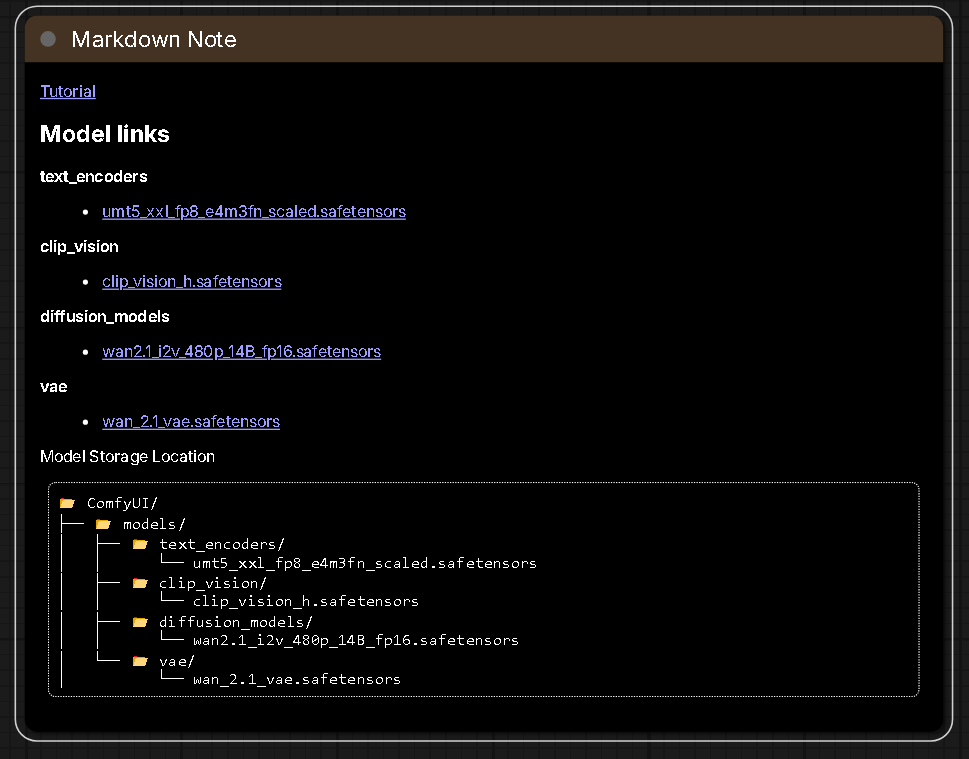
首次使用會需要到 Huggie Face 下載 AI 模型然後放到對應的 WSL 的 ComfyUI 目錄下
以下是對應的模型安裝的存放位置
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 text_encoders/
│ │ └── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ ├── 📂 clip_vision/
│ │ └── clip_vision_h.safetensors
│ ├── 📂 diffusion_models/
│ │ └── wan2.1_i2v_480p_14B_fp16.safetensors
│ └── 📂 vae/
│ └── wan_2.1_vae.safetensors
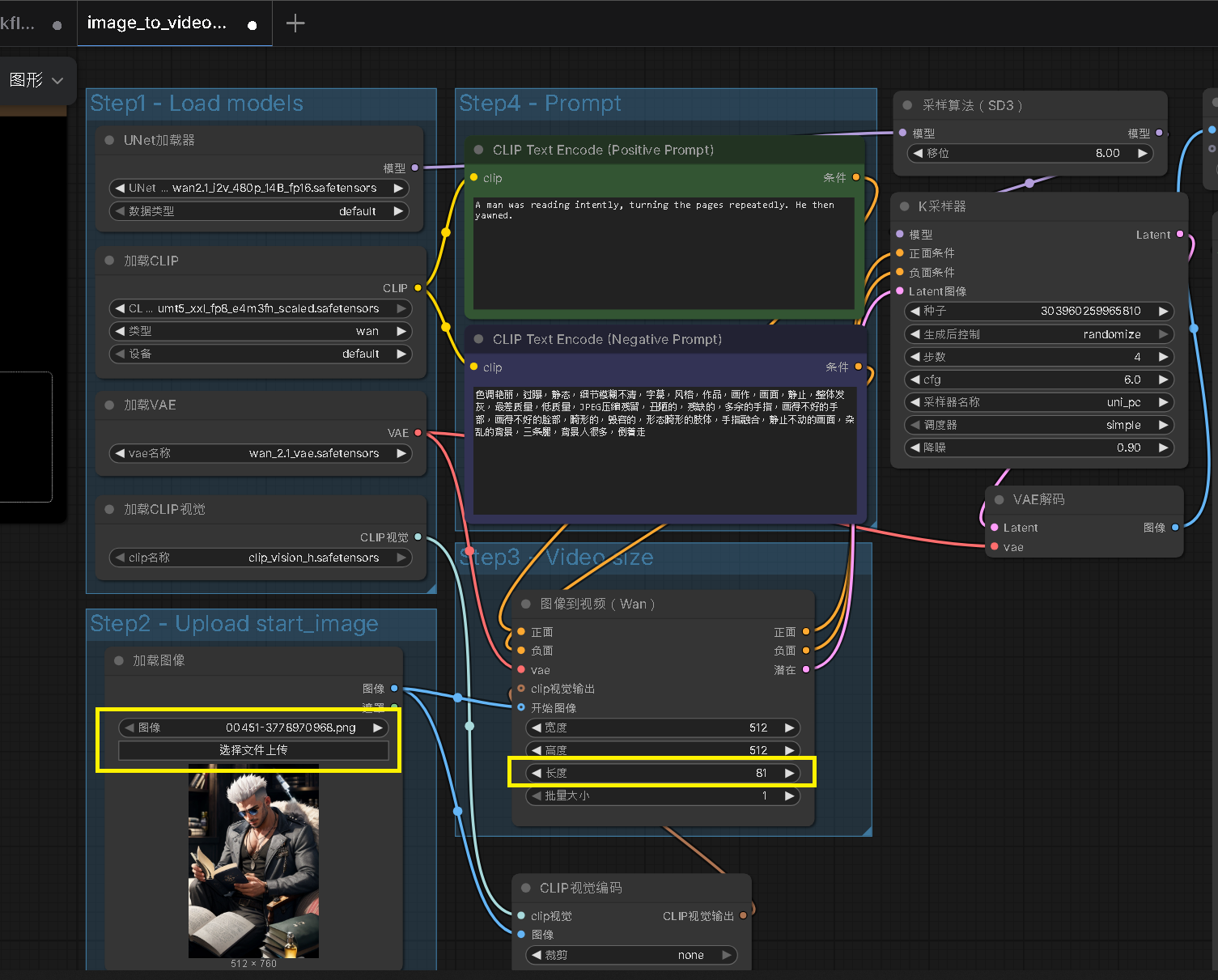
Step 6:導入模型 - 參數說明
以下是參數說明,為了可以順利運行,有三個地方需要手動參數調整
| Step 1. | Load modles | [可忽略] 預設AI模型放到正確目錄後,即可正常 |
| Step 2. | Upload start_image | [必須設定] 選擇一張圖片,作為圖生影片的基底 |
| Step 3. | Video size | [必須設定] 長度要除以 16 ,因此 81 約為 5 秒的影片(也是官方建議的預設長度) |
| Step 4. | Prompt | [必須設定] 這邊設定提示詞,正向、反向,依照自己需要填入 |
Step 7:導入模型 - 執行生成
參數設定好後,執行運行。
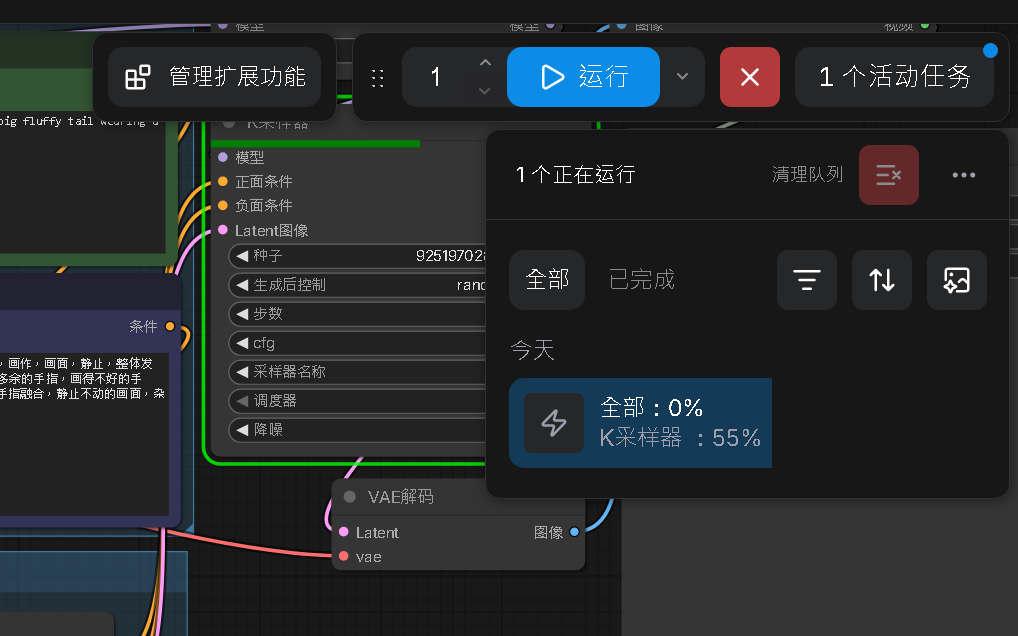
在執行的過程中 ComfyUI 的 Container Log 如果出現 Pin Error 是正常的
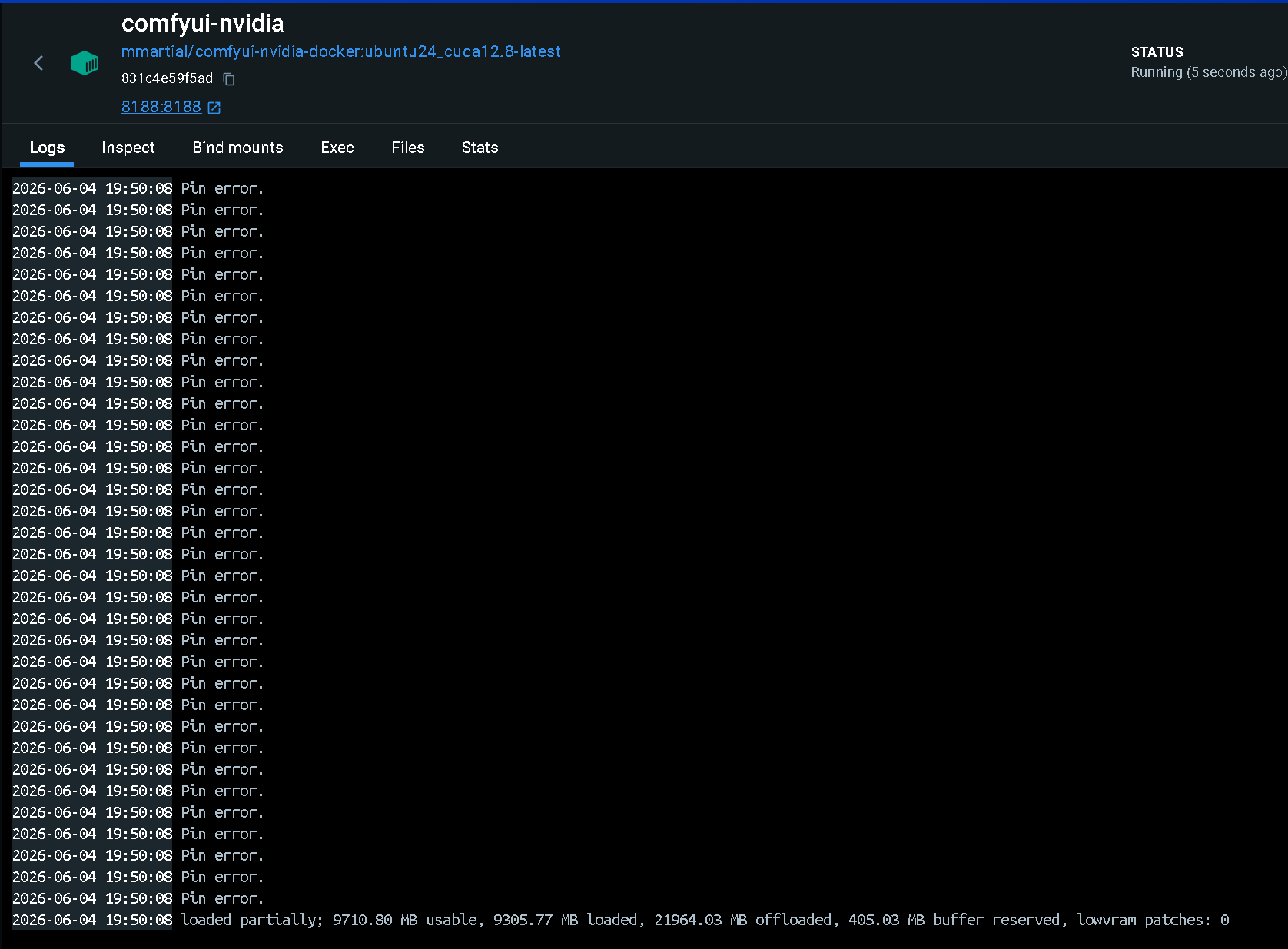
Step 8:導入模型 - 執行生成 - 說明 Pin Error
為何持續出現 Pin Error 正常,原因如下:
這個錯誤的核心原因在於 PyTorch 的 pin_memory=True 機制與 Windows WSL2 的記憶體管理產生了衝突
| 1. 什麼是 Pin Memory(鎖頁記憶體)? | 在正常的 Linux 實體主機上,AI 模型為了加快將數據從系統 RAM 傳送到顯示卡 VRAM 的速度, |
| PyTorch 會申請一塊「不能被交換到硬碟(Swap)」的固定實體記憶體(稱為 Pinned Memory)。 | |
| 2. WSL2 的限制 | Ubuntu 跑在 WSL2 虛擬化架構下,憶體已經開始用到了 Swap 空間,因而拋出 Pin error 或 Failed to pin 的警告。 |
PyTorch 非常聰明,當它嘗試 Pin 記憶體失敗時,它會自動倒退回普通的記憶體傳輸模式(非鎖頁模式)。因此出現此訊息是正常的
補充:數據從 RAM 傳到顯示卡的效率會稍微慢一點點,但絕對不會導致生成中斷或畫面崩潰。
Step 9:執行生成正常結果
預設正常的情況下,影片就會出來,但實際上我們在 首次執行 的過程出現了錯誤 comfyui-nvidia_init.bash: line 935: 308 Killed
解決方案在 第二部分 開始說明
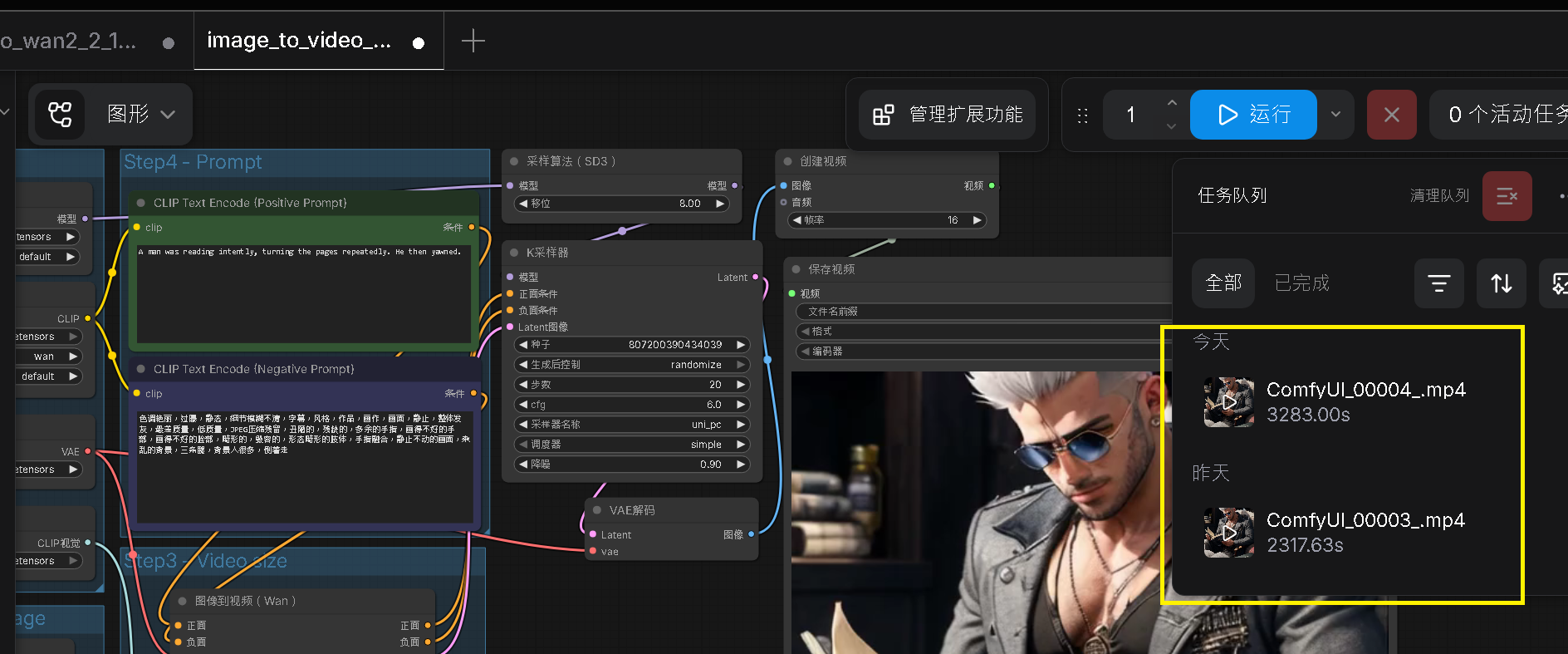
生成結果 - Youtube 播放:
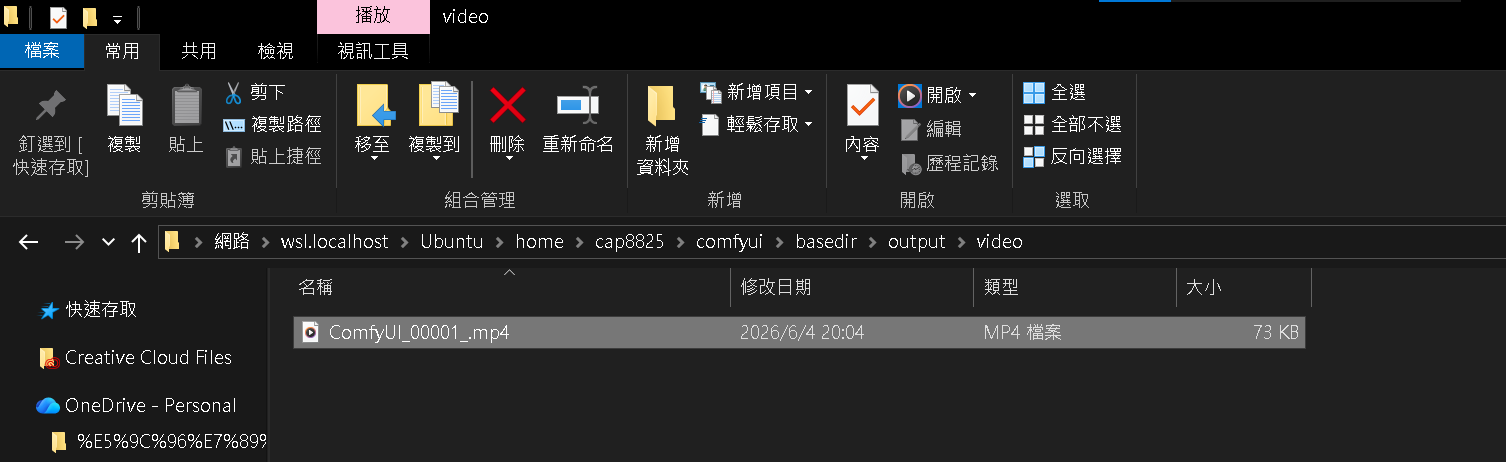
Step 10:輸出目錄
生成出來的檔案通常在 WSL 的 output 目錄下
.wsl.localhost\\Ubuntu\\home\\個人帳號\\comfyUI\\basedir\\output\\video
第二部分:遭遇問題 & 排除
Step 1:首次 Wan 2.1 無法執行的問題
如果環境 : Docker Desktop Windows ** + ** WSL2 ** + ** ComfyUI Wan ** + ** GPU, Memory 沒有很頂級,運行時極有可能出現此錯誤
comfyui-nvidia_init.bash: line 935: 308 Killed
本篇使用的規格(使次使用就會出現問題):
| 項目 | 規格 |
|---|---|
| GPU | 名稱 NVIDIA GeForce RTX 5070 (12G VRAM) |
| CPU | Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz,3192 Mhz,6 個核心,12 個邏輯處理器 |
| RAM | 48 GB |
| OS | Microsoft Windows 10 專業版 |
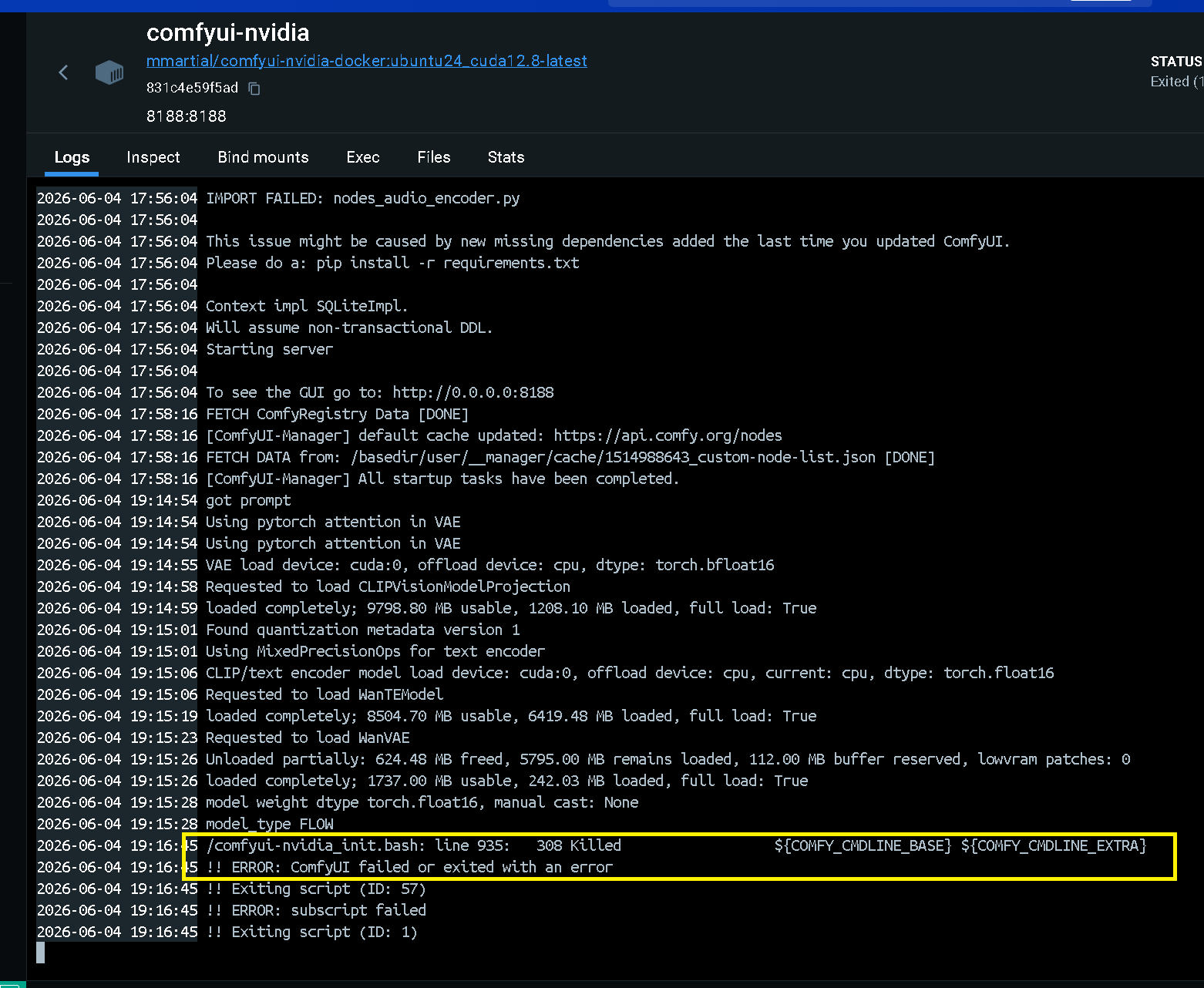
Step 2:執行過程記憶體不足
在生成影片時,監控 Container 狀態,可以發現記憶體全部被用盡,因此出現 308 Killed 記憶體不足的狀況
docker stats

Step 3:錯誤原因 - WSL2 記憶體限制步驟
硬體規格為 48G 記憶體在 Step 2. 只有使用 24GB 這是因為
觀察到 22.07GiB / 23.45GiB (94.14%)。
這代表 Docker 容器能拿到的記憶體上限被鎖死在 24GB 左右(精確來說是 WSL2 預設分給 Docker 的限制)。
而當 Wan 2.1 進行模型加載與權重切換時,記憶體瞬間衝頂,直接觸發了 OOM。
因此將 ** WSL2 的記憶體限制移除後 ** 就能順利排除此問題
Step 4:排除 WSL 限制 - 跳轉到設定檔目錄
Windows 系統中,鍵盤按下 WIN + R ,進入使用者個人資料夾
%userprofile%
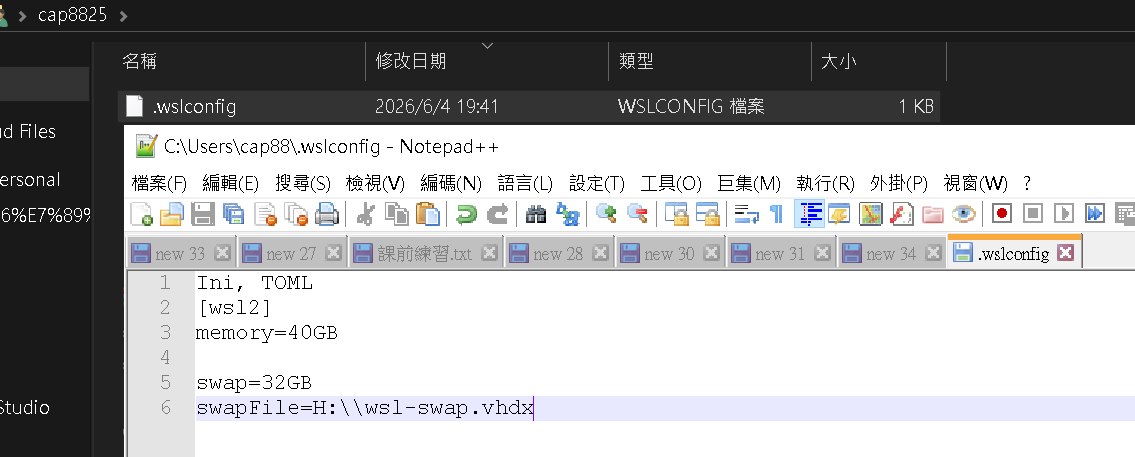
Step 5:排除 WSL 限制 - 新增或修改 .wslconfig
若沒有該檔案,則自行新增
.wslconfig

新增後,打開檔案,並且將以下貼上
Ini, TOML
[wsl2]
# 限制 WSL2 使用的記憶體大小,建議直接給到實體記憶體的 75% - 80%
# 假設實體 RAM 是 48GB,可以給 36~40GB (75%上下)
memory=40GB
# 開啟 Swap 虛擬記憶體當緩衝,防止突發性記憶體衝頂
swap=32GB
# 硬碟當虛擬記憶體 : 不寫這行也可以,Windows 會幫你無中生有,但寫了可以更好控制虛擬硬碟存放位置
swapFile=H:\\wsl-swap.vhdx
#後面的是備註說明,實際上可以如圖,乾淨的設定值
Step 6:排除 WSL 限制 - 重啟 WSL
開啟 Windows CommandLine,將 WSL 重新啟動,以便啟用新設定
wsl --shutdown

Step 7:排除 WSL 限制 - 重啟 Doekcer Desktop
並且這時 Dokcer Desktop 需重新啟動
Step 8:排除 WSL 限制 - 檢查容器記憶體空間
全都重啟後,可檢查容器使用記憶體配置,最大上限已經變為我們設定的 40G
docker stats
comfyui-nvidia_init.bash: line 935: 308 Killed 的問題至此可以排除

第三部分:遺留問題
Step 1:運算過慢 - 仍可優化
目前運算 5 秒鐘的影片,20步約耗費 25 分鐘,實際上耗費的成本太大了
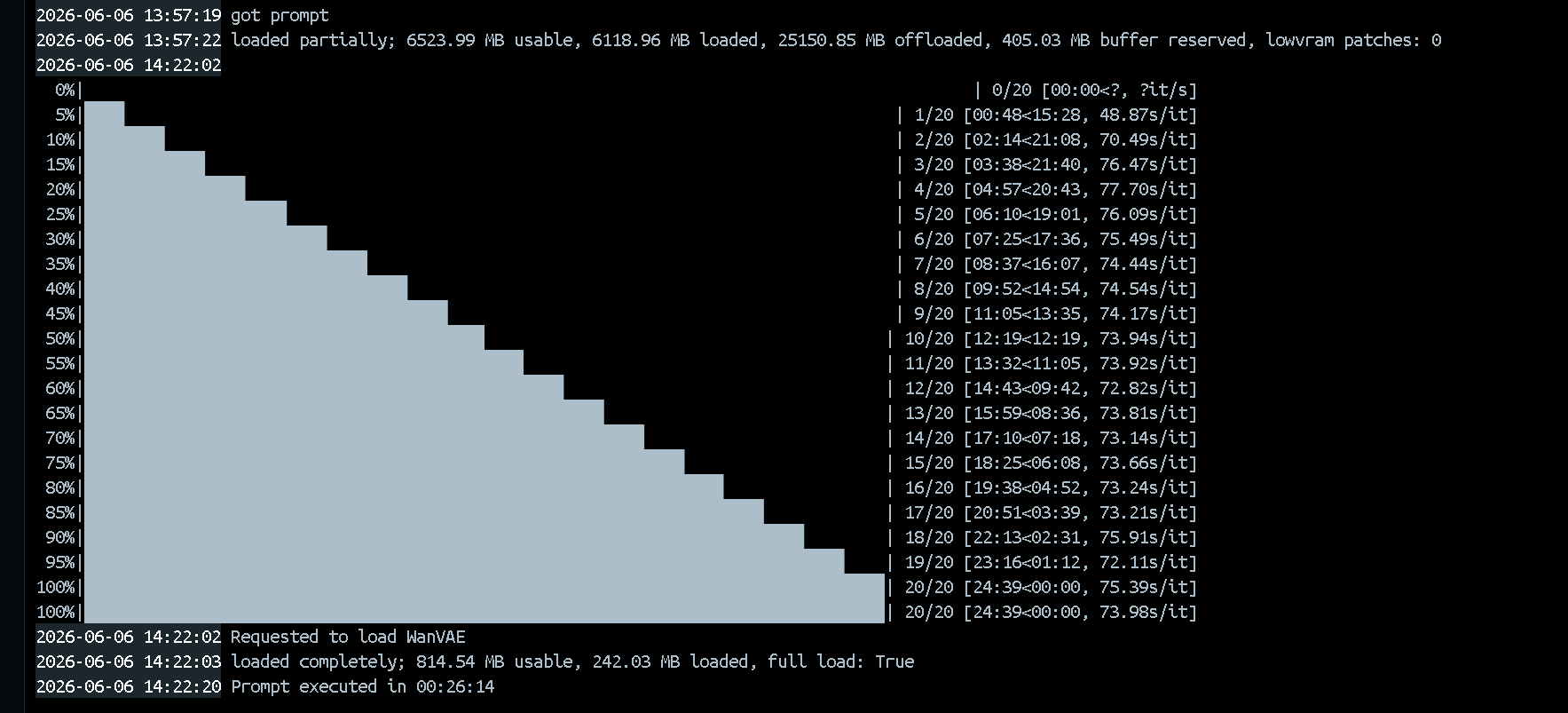
後續仍可朝向以下的方向進行優化(不犧牲影片品質的加速圖生成影片):
| 方法 | 具體作法 |
|---|---|
| 1. LightX2V LoRA | LightX2V LoRA(Steps 4步)屬於蒸餾模型,強迫 4 步版本的輸出去模仿 20 步的結果,大幅提高效能 |
| 2. TeaCache | TeaCache 是一種無需訓練的快取加速方法,透過估算模型在不同時間步之間輸出的差異,在相似的時間步複用快取結果而非重新計算 |
| 3. SageAttention | SageAttention 透過對 Attention 運算進行量化(使用較低精度如 8-bit),在幾乎無損精度的情況下加速 Transformer 的 Attention 計算 |