日期:2025年 10月 18日
標籤: Tesseract Tesseract OCR IronOcr OCR Asp.NET Core Asp.NET Core Web MVC C# Web
摘要:C# 學習筆記
範例所需:1. Visual Studio 2022 以上版本
2. IronOCR (Ver:2025.8.6)
範例檔案:本篇範例代碼
相關參考:0101. ASP.NET Core 整合 Tesseract OCR:從原始圖片到文字識別的完整實作
解決問題:Tesseract OCR 在低解析度圖片時辨識效果較差,可採用付費的 IronOCR 解決此問題
基本介紹:本篇分為四大部分。
第一部分:IronOcr 介紹
第二部分:IronOcr 取得測試Key
第三部分:範例專案說明 + 實作
第四部分:DEMO 成果
第一部分:IronOcr 介紹
Step 1: IronOcr 基本介紹
官網連結,首頁對 C# 的支持,專注於圖像
OCR for C# 用於掃描和閱讀圖像及 PDF
.NET OCR 庫,包含 127 多個全球語言包
以文字、結構化數據或可搜索的PDF文件輸出
支持 .NET 9、8、7、6、Core、Standard、Framework
簡言之:Dotnet 生態系很適合使用 IronOcr 做圖像辨識
特色點
| 特性 | 說明 |
|---|---|
| 高精準度 | 基於 Tesseract 優化,OCR 準確率達 99.8% |
| 跨平台 | 支援 .NET 多版本,運行於 Windows/Mac/Linux 及 Docker、雲端 |
| 多語與條碼 | 支援超過 125 種語言 + 條碼與 QR code |
| 強大預處理功能 | 去噪、矯正、增強解析度等功能提升 OCR 成效 |
| 多樣輸出格式 | 純文字、結構化資料、Searchable PDF、hOCR/XHTML |
| 部署便利 | NuGet 或 DLL,支援多種 .NET 應用類型 |
| 開發者口碑 | 多數推崇其精準度、彈性與穩定性 |
Step 2: IronOcr - 優缺點
基於上述特色,整理出以下優點:
| 特性 | 說明 |
|---|---|
| 安裝容易、快速上手 | API 設計簡潔,開發者幾乎可以「開箱即用」、用 Nuget 不需要額外下載語言包與手動設定 |
| 準確度高 | 基於 Tesseract 3/4/5,但經過 IronSoftware 的優化,比原生 Tesseract 更準確,並且支援內建圖片前處理 |
| 多語言支援強大 | 支援超過 125 種語言,包含中文、日文、韓文、阿拉伯文等。 |
| 跨平台支援 | 可在 Windows / Linux / macOS / Docker / 雲端(Azure、AWS Lambda) 執行。 |
| 功能完整 | 文字辨識,還能輸出 Searchable PDF |
| 性能優化 | 提供非同步、多執行緒支援,能處理大量文件。 |
但是延伸以下缺點:
| 特性 | 說明 |
|---|---|
| 商業授權費用高 | IronOCR 不是免費,免費版有功能限制(例如結果有水印或字數限制) |
| 準確度高 | API 設計簡潔,開發者幾乎可以「開箱即用」、用 Nuget 不需要額外下載語言包與手動設定 |
| 效能受影像品質影響 | 雖然有內建前處理,單還是需高辨識率的圖片 |
| 套件體積偏大 | NuGet 套件下載安裝後可能上百 MB,比較肥大 |
| 依賴 IronSoftware 生態 | 他們也有 IronPDF、IronBarcode 等套件,通常綁在一起推銷。 |
雖然品質較 Tesseract 好,但需要收費對維運支出是一筆不小的費用。
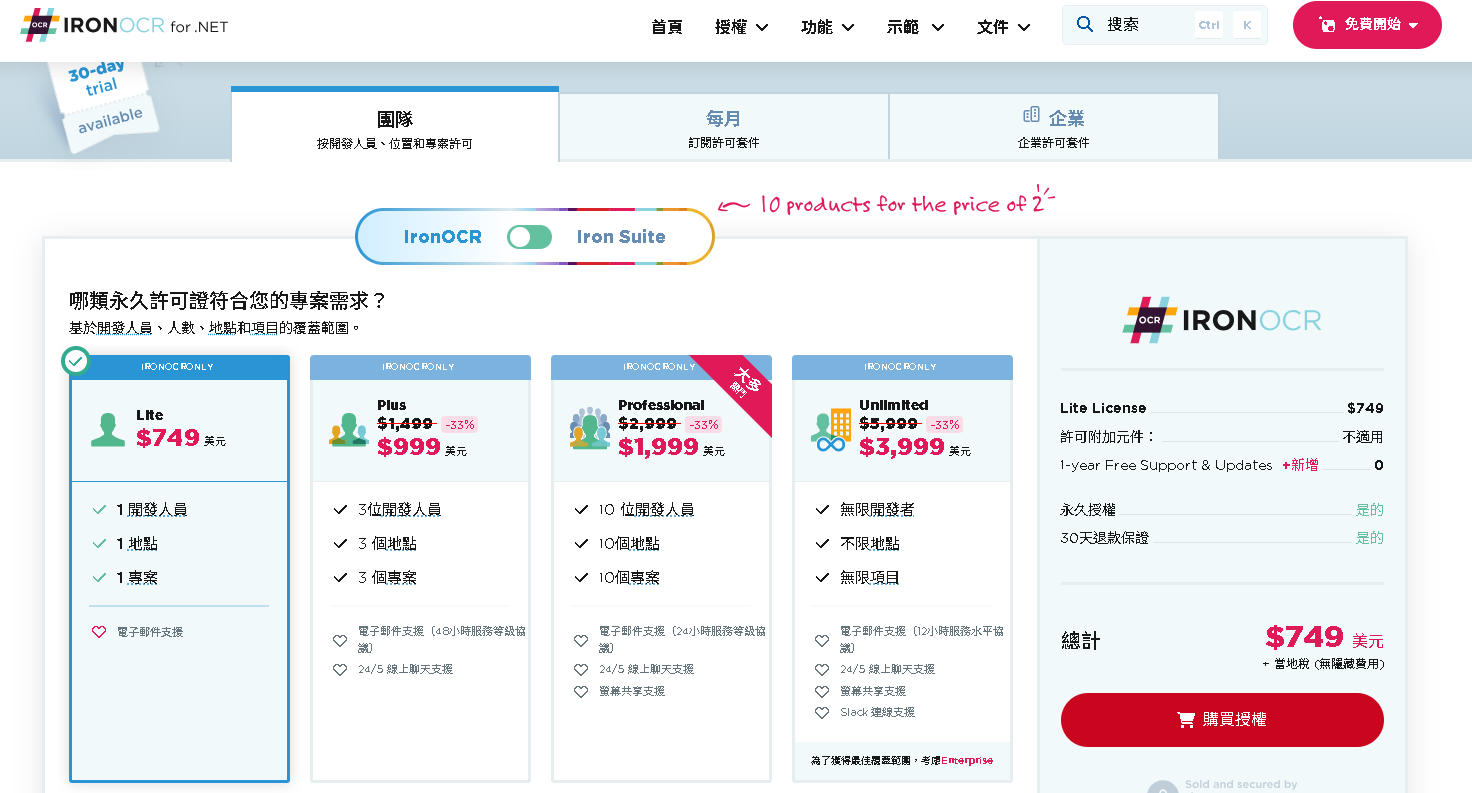
Step 3: IronOcr - 收費方式
官方授權的收費頁面,價格至少幾百美金起跳
以下為買斷制的整理 CP 值:
| 使用情境/需求 | 推薦方案 | 內容 | 為何划算? |
|---|---|---|---|
| 單人/單專案 | Lite(US$ 749) | 1 開發者 / 地點 / 專案 | 最低成本,永久授權 |
| 小團隊/多專案 | Plus(US$ 999) | 3 開發者 / 地點 / 專案 | 成本稍高但資源三倍擴展 |
| 中型團隊/正式專案開發 | Professional(US$ 1,999) | 10 開發者 / 地點 / 專案 | 支援大量開發人員與專案 |
| 大型企業/OEM 或離線控制部署 | Unlimited + 加購項目 | 無限制開發者 / 地點 / 專案 | 無限資源 + 特定授權最佳符合需求 |
| 希望未來更新與支援保障 | 延長支援選項 | 可議 | 一次付費擁有多年更新與支援保障 |
最便宜的單人、單專案就會要 749 美元 (含 1 年支援更新,超過 1 年後可以繼續用授權的 Key 但是就不能更新軟體了)
Step 4: IronOcr - 激活金鑰補充
License 需要在首次激活,後續就可以離線使用,但依照使用情境,可能大多解析圖片的情況都是需要網路的
| 流程階段 | 網路需求 | 使用情況 |
|---|---|---|
| 首次啟用 License | ✅ | 需要網路驗證 Key |
| 日常 OCR | ❌ | 完全離線使用,可永久用 |
| 更新 / 新功能 | ✅ | 下載新版或語言包 |
第二部分:IronOcr 取得測試Key
Step 1:登入官網
進入官網連結後,依序填入資訊
| 1. 輸入自己的信箱 (範例用 Gmail) |
| 2. 送出 |
Step 2:成功請求
若可以正常送出,則出現下圖資訊
Step 3:打開信箱
依照地區的不同,收到信的時間可能或長或短,將以下的金鑰 複製,後續代碼中會用到

第三部分:範例專案說明 + 實作
Step 1: 範例專案說明
打開本篇範例代碼後,架構基本分成以下:
| 1. 初始化配置 | : | 依賴注入用到的 Service |
| 2. 業務邏輯服務 | : | 實現如何操作 IronOCR 擷取圖片的方法 |
| 3. 靜態協助 | : | 讀取對應圖片檔案的名稱,靜態變數 |
| 4. 控制器 | : | 將使用 IronOCR 擷取的結果傳至 Web 檢視器 |
| 5. Web 檢視器 | : | 展示 IronOCR 擷取圖片的差異 |
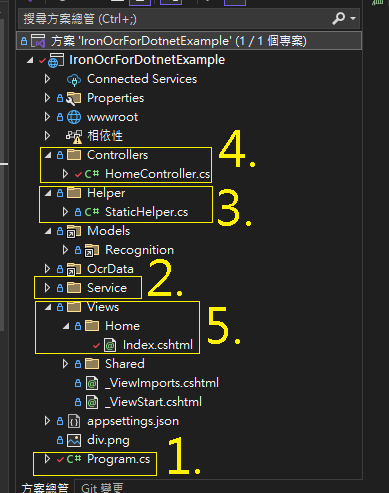
Step 2: Nuget 安裝套件
先從 Nuget 上安裝 IronOCR 套件,這邊安裝 2025.8.6 版本
IronOcr
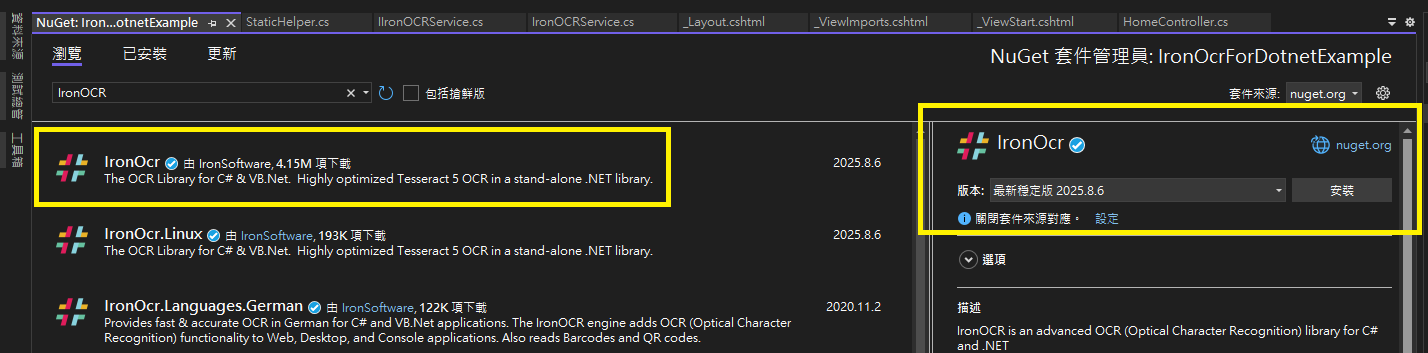
Step 2: 安裝語言包
與 Tesseract 的安裝語言包的方式不太一樣,IronOcr 支持 Nuget 安裝語言包
分別安裝以下簡體中文,本篇範例會用到
※英文是預設不用安裝
IronOcr.Languages.Chinese
IronOcr.Languages.ChineseSimplified

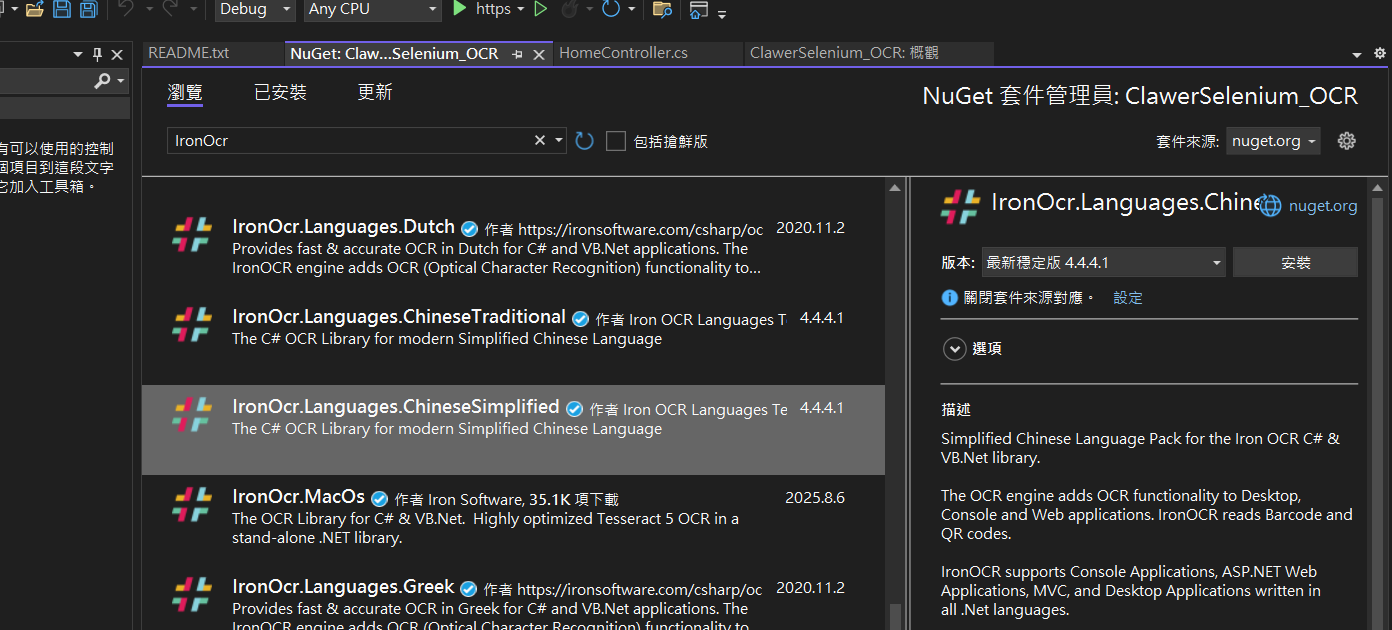
Step 3: 安裝完成 - 提供使用說明
安裝完 IronOCR 套件後,會預設開啟 C# 的使用範例說明,但預設說明沒有使用金鑰的方法
後面代碼範例會繼續說明如何使用金鑰
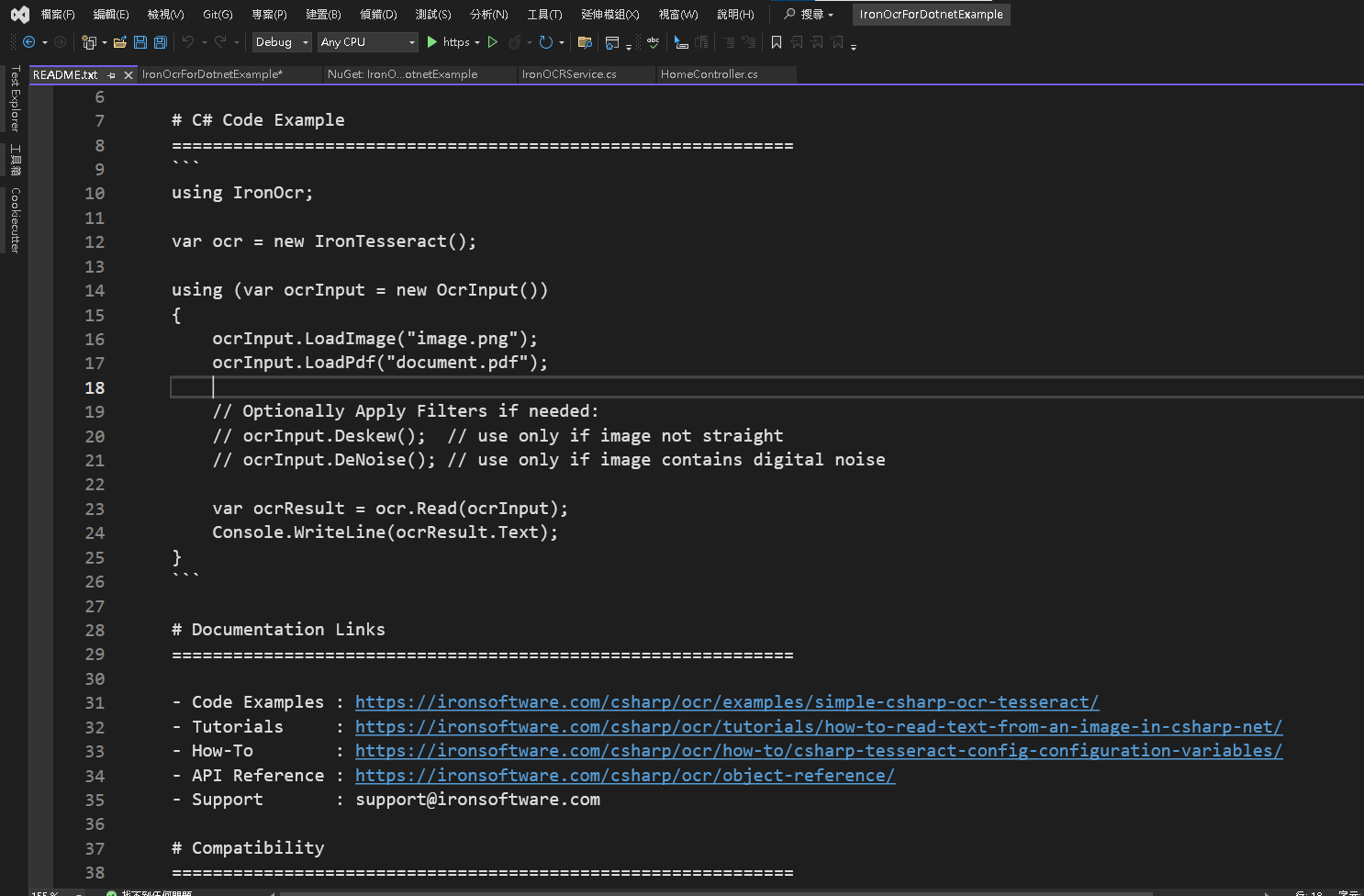
Step 4:範例代碼說明
以下為對應代碼 IronOcrService.cs 流程,有 4 大項步驟
IronOcr 最大的優勢是專門為 Ocr 對象進行圖片處理
| 1. 準備好金鑰 | : | 將註冊拿到的金鑰貼上 |
| 2. 設定金鑰 | : | 設定金鑰的方式 |
| 3. 可以選擇多個語言,選擇英文 + 簡中 | : | 語言包可以用疊加的方式,順序很重要,會影響辨識語言優先級 |
| 4. OCR 工作 | : | 貼心的圖片處理 + OCR |
public class IronOCRService : IIronOCRService
{
// 1. 準備好金鑰
private readonly string _IronKey = $@"IRONSUITE.xxxxxxxxx";
private readonly ILogger<IronOCRService> _logger;
public IronOCRService(ILogger<IronOCRService> logger)
{
_logger = logger;
}
public string IronOCR()
{
// 2. 設定金鑰
IronOcr.License.LicenseKey = _IronKey;
var ocr = new IronTesseract();
var ocrResult = string.Empty;
// 3. 可以選擇多個語言,選擇英文 + 簡中
ocr.Language = OcrLanguage.EnglishBest;
ocr.AddSecondaryLanguage(OcrLanguage.ChineseSimplifiedBest);
try
{
// 4. 開始 OCR 工作
using (var ocrInput = new OcrInput())
{
// 4-1. 設定 IronOCR 會為圖片處理以下工作
ocrInput.DeNoise();// a. 去除雜訊
ocrInput.Deskew(); // b. 自動校正傾斜
ocrInput.Invert(); // c. 反色 (黑底白字)
// 4-2. 執行 OCR (會套用上述的圖片處理)
ocrInput.LoadImage("div.png");
ocrResult = ocr.Read(ocrInput).Text;
}
}
catch (Exception ex)
{
Console.WriteLine(ex);
}
return ocrResult;
}
}
第四部分:DEMO 成果
Step 1:測試圖片 - 低解析度圖片
圖片同這篇範例:0101. ASP.NET Core 整合 Tesseract OCR:從原始圖片到文字識別的完整實作
使用較低解析度的圖

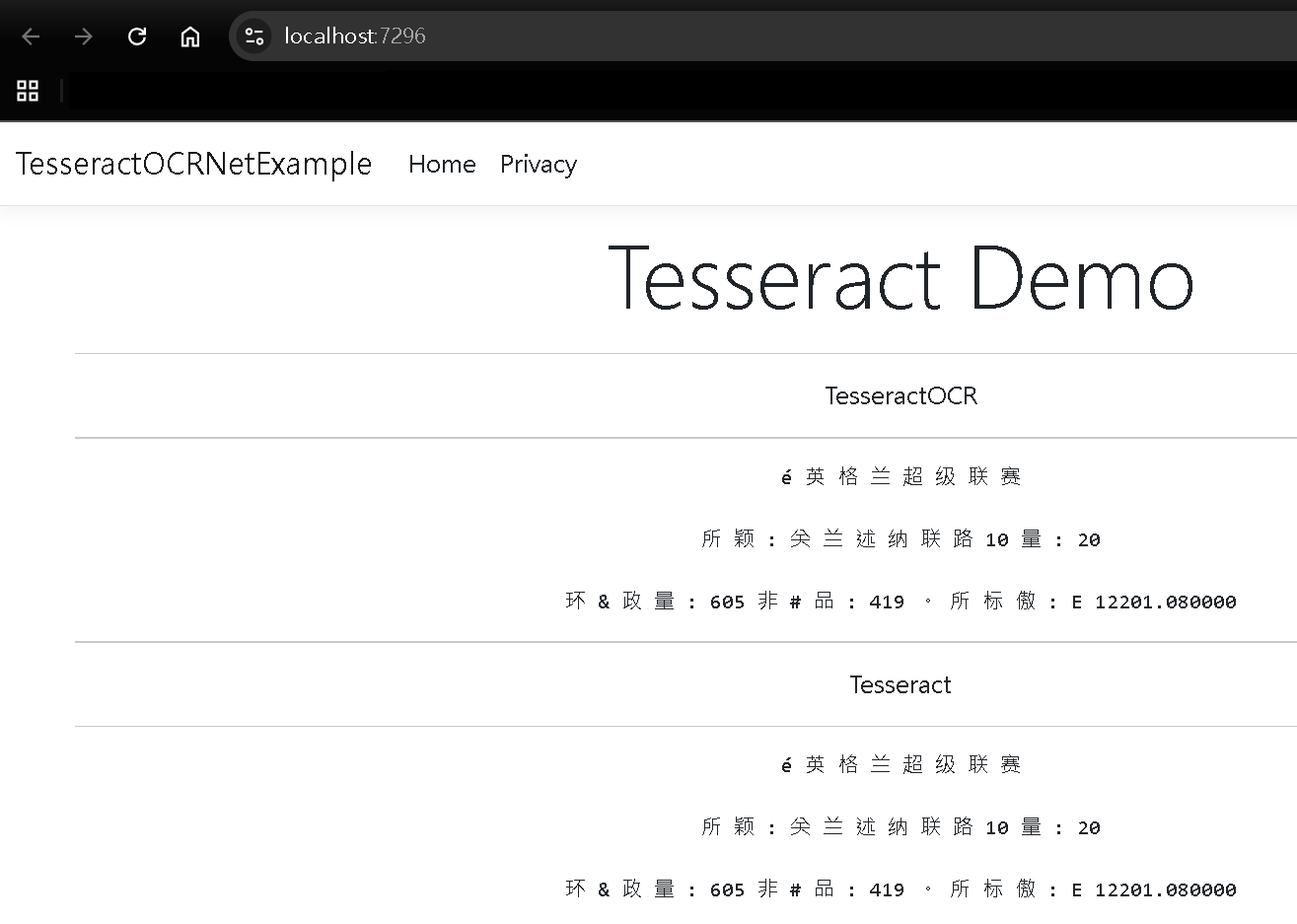
Step 2:執行成果 - 分析效果卓越
對於低解析的圖片,雖然簡體中文字無法分析得清楚,但是數值已經很清楚的,對於標點符號 , 與 . 可以精確地分出
IronOCR:
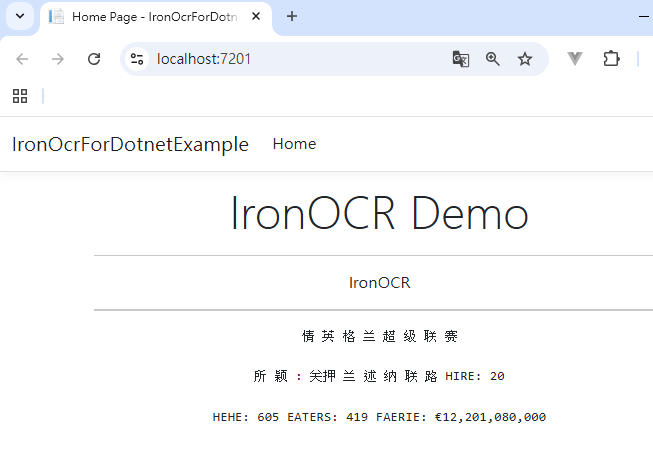
對比上次使用 Tesseract 與 TesseractOcr 並用低解析圖片,可以明顯感到兩者差異
TesseractOcr: