日期:2025年 10月 04日
標籤: Tesseract Tesseract OCR OCR Asp.NET Core Asp.NET Core Web MVC C# Web
摘要:C# 學習筆記
範例所需:1. Visual Studio 2022 以上版本
2. Tesseract (Ver:5.2.0)
3. TesseractOCR (Ver:5.5.1)
範例檔案:本篇範例代碼
解決問題:1. 將擷取的圖片進行 Tesseract OCR 辨識
2. 說明當前主流的 Tesseract 與 TesseractOCR Libary 的差異
基本介紹:本篇分為五大部分。
第一部分:Tesseract 與 TesseractOCR 介紹
第二部分:範例專案架構
第三部分:Tesseract 準備工作
第四部分:Tesseract 與 TesseractORC 代碼實作
第五部分:DEMO 成果
第一部分:Tesseract 與 TesseractOCR 介紹
Step 1: Tesseract OCR 簡介
以下介紹來自於Wiki
Tesseract是光學字元辨識引擎,支援多種作業系統。Tesseract是基於Apache授權條款的自由軟體,自2006年起由Google贊助開發。
2006年,Tesseract被認為是最精準的開源光學字元辨識引擎之一。
簡言之:可以透過 Tesseract OCR 做圖片辨識,轉為文字

Step 2: Tesseract 的優缺點
從早期的低準確度(2006 ~ 2025年至今),Tesseract OCR 是不斷進步的,時至今日有以下優點:
| 開源免費 | 免費使用,沒有授權費用或使用限制,適合各種規模的專案 |
| 高準確度 | 經過多年發展和優化,對於 清晰、標準字體 的文字識別準確度可達 95% 以上 |
| 多語言支援 | 內建支援繁體中文、簡體中文、英文等多種語言,滿足國際化需求,當前至少有 100 種語言 |
| 社群活躍 | 擁有龐大的開發者社群,文件完善,問題容易找到解決方案 |
| 整合容易 | 提供 .NET 封裝套件,可以輕鬆整合到 ASP.NET Core 專案中。 |
仍遺留的缺點
| 識別限制 | 對手寫文字識別效果差、需要圖片高清晰,才有一定的準確度 |
| 效能考量 | 處理大圖片時較耗時,並且記憶體占用較大 |
| 技術門檻 | 參數調校需要經驗,通常要更深入需要看 Github 上的 doc 文件 |
| 部署困難 | 部署到跨平台環境需要做額外的配置,並且在本地使用需要一定的基礎設定(本篇會說明) |
Step 3: 與主流雲服務的 OCR 方案比較
目前打開 Google 翻譯,用相機模式,可以自動翻譯到其他國家的語言,也是因為商業用途對用於戶的體驗更好。
Tesseract 是給想免費解決某些應用場景問題而使用,如果要更專業更強大的 OCR 來進行高精確度的圖片轉文字,建議還是需要付費。
| 比較項目 | Tesseract | Azure OCR | Google Vision | AWS Textract |
|---|---|---|---|---|
| 成本 | 免費 | 付費 | 付費 | 付費 |
| 準確度 | 85-95% | 95-98% | 95-99% | 95-98% |
| 中文支援 | 良好 | 優秀 | 優秀 | 良好 |
| 手寫識別 | 差 | 良好 | 優秀 | 良好 |
| 部署方式 | 本地部署 | 雲端 API | 雲端 API | 雲端 API |
| 客製化 | 高 | 中 | 低 | 中 |
| 處理速度 | 中等 | 快 | 快 | 快 |
Step 4: Tesseract OCR 應用場景
如果有符合以下開發需求,那麼可以考慮使用 Tesseract OCR
| 應用場景 | 說明 |
|---|---|
| 自動化資料擷取 | 定期從特定網站擷取商品價格、新聞標題、股票資訊等結構化數據。 |
| 網頁內容監控 | 監控競爭對手網站的內容變化,或追蹤特定資訊的更新。 |
| 驗證碼識別 | 在自動化測試或資料爬取過程中識別簡單的驗證碼。 |
| 文件數位化 | 將網頁中的 PDF 預覽圖或掃描文件轉換為可搜尋的文字。 |
針對上述的應用場景,也仍需考量以下將面臨的挑戰:
| 應用場景 | 遇到的挑戰 |
|---|---|
| 自動化資料擷取 | 現代 Web 對於重要的資料,有很多防禦性編程在前端中,需要先做預處理解決 web 上的 dom 元件 |
| 網頁內容監控 | 網頁內容會不斷變化,當爬蟲擷取的圖片有大變化時,原本的特定解析判斷會導致要重寫 |
| 驗證碼識別 | 驗證碼會有雜訊,圖片不清晰,圖片轉文字辨識度會下降 |
| 文件數位化 | 文字過度緊密會導致辨識錯誤,文件中的圖片亦會導致辨識成別種東西需要額外處理 |
針對上述的挑戰,可以考慮以下方向進行應對策略:
| 應用場景 | 應對策略 |
|---|---|
| 自動化資料擷取 | Selenium 等候策略 (WebDriverWait) |
| 實作重試機制和錯誤恢復 | |
| 添加 headless browser 模擬真實使用者 | |
| 網頁內容監控 | 建立基準截圖比對機制 |
| 使用相對位置而非絕對坐標 | |
| 實作版面變化自動適應 | |
| 驗證碼識別 | 圖片預處理(去噪、二值化、膨脹腐蝕) |
| 已支援 LSTM 可考慮結合深度學習模型 | |
| 文件數位化 | 版面分析和區域分割 |
| 表格專用識別演算法 | |
| 結合人工校對流程 |
無論如何,Tesseract 的最大對手是成本,當想要使用圖片識別並且可以持續使用,長遠看來會是大量的成本(時間、精力、金錢)
要針對自己解決的問題而決定是否使用
Step 5: Tesseract OCR 與 Tesseract
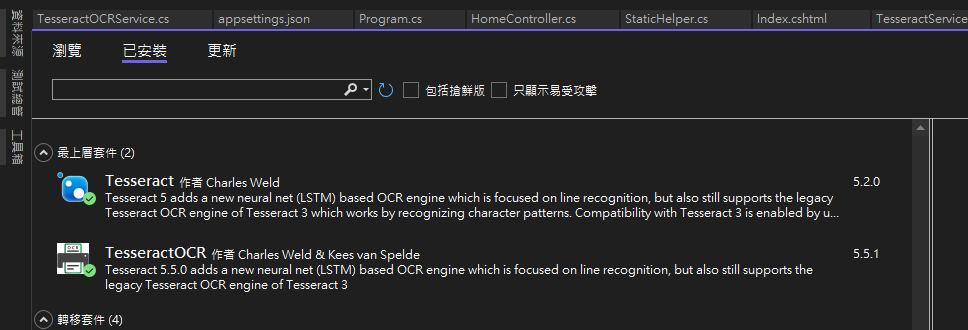
在 Nuget 中,我們可以看到有 2 種版本的 Tesseract Libary,在使用前可以
| Tesseract | Tesseract OCR | |
|---|---|---|
| 封裝 | charlesw/tesseract | Sicos1977/TesseractOCR |
| 維護狀況 | 停更(2016) | 持續更新 |
| 支援 Tesseract 版本 | Tesseract 3.x | Tesseract 4.x/5.x |
| 平台 | Windows | Windows/Linux/macOS |
| 特點 | 穩定但舊,不支援 LSTM | 跨平台、支援 LSTM、新功能 |
| 備註 | 基於 Tesseract 改良 |
兩者都是 Google 維護的開源專案,但早期的 OCR 都是使用 charlesw/tesseract (也就是網路上大部分文章都使用這個 Libary)
現在都傾向使用 跨平台、更高效能 的 Sicos1977/TesseractOCR
連結:
Sicos1977/TesseractOCR
charlesw/tesseract
Nuget 會看見:
第二部分:範例專案架構
Step 1: 範例專案說明
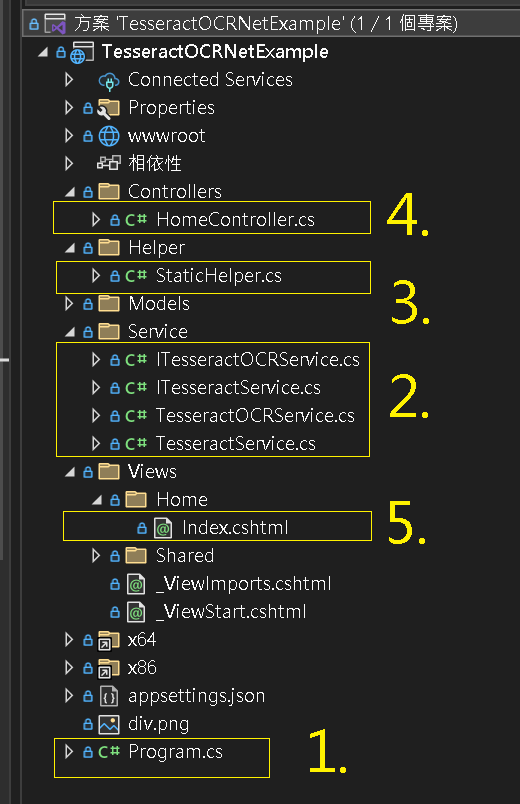
打開本篇範例代碼後,架構基本分成以下:
| 1. 初始化配置 | : | 依賴注入用到的 Service |
| 2. 業務邏輯服務 | : | 實現如何操作 Tesseract 與 TesseractOCR 擷取圖片的方法 |
| 3. 靜態協助 | : | 讀取對應圖片檔案的名稱,靜態變數 |
| 4. 控制器 | : | 將擷取 OCR 的結果傳至 Web 檢視器 |
| 5. Web 檢視器 | : | 展示 Tesseract 與 TesseractOCR 擷取圖片的差異 |
第三部分:Tesseract 準備工作
Step 1: Nuget 安裝套件
先對自己的專案安裝 Nuget 套件:
Tesseract
TesseractOCR
Step 2: 安裝語言包
到Tesseract 的 Github 語言包下載語言包,這篇文章會用到簡體中文、英文
以下 2 個分別是簡體中文、英文
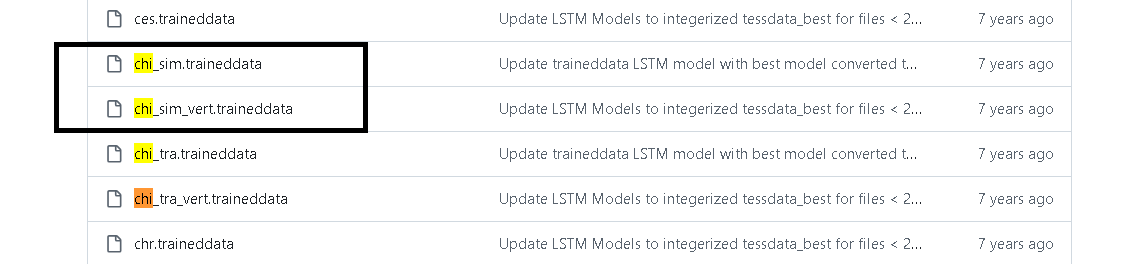
chi_sim.traineddata
eng.traineddata
找到對應的檔案下載:
Step 3: 語言包放進專案目錄下
將語言包放進自己專案底下的目錄中,這邊使用 Source\tessdata\ 資料夾下
$\Source\tessdata\chi_sim.traineddata
$\Source\tessdata\eng.traineddata
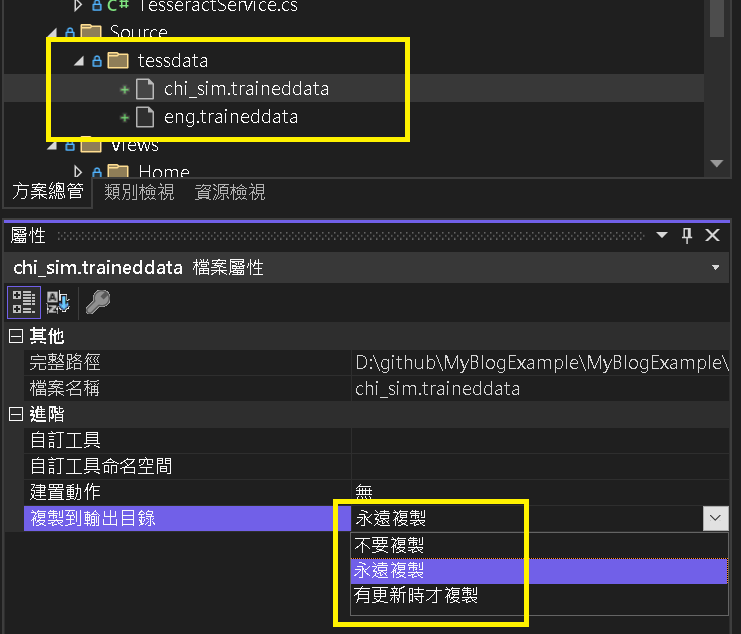
Step 4: 設定語言包檔案
進入 Visual Studio 中,對專案中的上述 2 個語言包檔案 -> 複製到輸出目錄 -> 永遠複製
編譯成功時,會自動輸出語言包
Step 5: 準備圖檔
為了便於說明,這邊使用此網站的圖片作為辨識 雷速體育,其中英超資料的一段截圖
※此網站專注提供運彩資訊,為了防止機器人爬蟲,有很好的防禦力,通常應對這類型的網站進行爬取資料,OCR 就是一種解決方案

第四部分:Tesseract 與 TesseractORC 代碼實作
Step 1:經典 Tesseract
以下為對應代碼 TesseractService.cs 流程,要注意的是要多語言使用的是 + 符號組成
/// <summary>
/// 使用 Tessract 進行 OCR 分辨文字
/// </summary>
/// <returns></returns>
public string TesseractVersionImage()
{
// 1. 語言包路徑
var tessDataPath = Path.Combine(AppDomain.CurrentDomain.BaseDirectory, $@"Source\tessdata");
// 2. 解析的文字內容
var result = string.Empty;
try
{
// 3. 設定語言包,必須使用副檔名前的名稱,並且用 + 才能支持多語言
using (var engine = new TesseractEngine(tessDataPath, "eng+chi_sim", EngineMode.Default))
{
// 4. 讀取圖片
using (var img = Pix.LoadFromFile(StaticHelper._ImageFileName))
{
// 5. 執行 OCR 結果
using (var page = engine.Process(img))
{
result = page.GetText();
}
}
}
}
catch (Exception ex)
{
Console.WriteLine(ex);
}
return result;
}
Step 2:近代優化 TesseractOCR
以下為對應代碼 TesseractServiceOCR.cs 流程,多語言則是 List
/// <summary>
/// 使用 TessractOCR 進行 OCR 分辨文字
/// </summary>
/// <returns></returns>
public string TesseractOCRVersionImage()
{
// 1. 語言包路徑
string tessDataPath = Path.Combine(AppDomain.CurrentDomain.BaseDirectory, $@"Source\tessdata");
// 2. 解析的文字內容
var result = string.Empty;
try
{
// 3. 設定語言包,必須使用副檔名前的名稱,並且用 List 才能支持多語言
var languages = new List<Language>() { Language.English, Language.ChineseSimplified };
using (var engine = new Engine(tessDataPath, languages, EngineMode.Default))
{
// 4. 讀取圖片
using (var img = TesseractOCR.Pix.Image.LoadFromFile(StaticHelper._ImageFileName))
{
// 5. 執行 OCR 結果
using (var page = engine.Process(img))
{
result = page.Text;
}
}
}
}
catch (Exception ex)
{
Console.WriteLine(ex);
}
return result;
}
第五部分:DEMO 成果
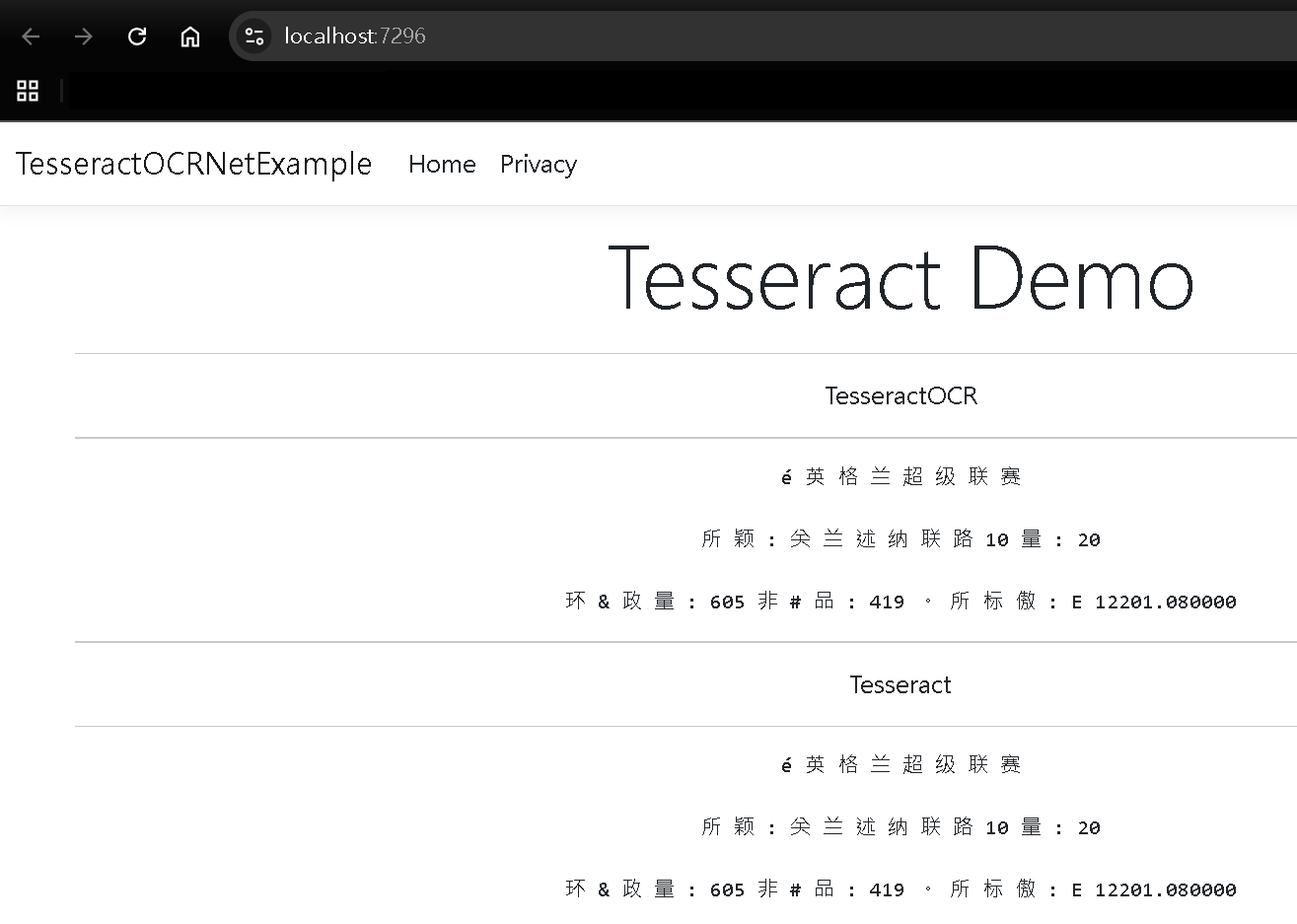
Step 1:執行成果 - 低解析度圖片
啟動代碼執行後,預設會解析以下圖片
可以看到解出的成果,能夠分辨,但無法完整的解出,但是數字的部分在爬蟲是可以再進行後處理。
Step 2:執行成果 - 提高圖片解析度
但是用另一張較高解析度的圖片,以下:

可以看到解出的成果,這次文字有 8 成可以解釋,並且符號 , 也能順利顯示,對於圖片的清晰度影響很大。

Step 3:未來仍可持續改良
若要更進一步改良效果,可以從 TesseractOCR官方說明文件中嘗試調校參數