日期:2025年 06月 28日
標籤: C# Asp.NET Core Windows Forms ILGPU
摘要:效能議題
應用所需:1. 顯示卡 (本篇範例 Nvdia 2060 12G)
2. Visual Studio 2022 Asp.net Core
3. 引用 ILGPU C# 套件實作 GPU 平行運算
範例檔案:本篇範例代碼
相關參考:0008. 康威生命遊戲(Game Of Life) - 細胞自動機模擬與程序化生成
探討問題:CPU 適合控制邏輯與少量運算;GPU 擅長大規模資料的平行處理。比較 2 者在康威生命遊戲的執行下效能差異。
基本介紹:本篇分為四大部分。
第一部分:定義目標與範圍
第二部分:測試範例代碼
第三部分:執行測試
第四部分:分析結果 & 結論
第一部分:定義目標與範圍
Step 1:測試目標
細胞由小而大,當細胞量大時運行處理效率提升比較,並且以 600 世代,CPU 與 GPU 的耗費時間多久才能完成
※每秒最快執行 10 次 0.1 秒觸發一次世代更新
| 像素 | 細胞數量 | 計算時間 |
| 512 * 512 | 262,144 | 600 次 |
| 1024 * 1024 | 1,048,576 | 600 次 |
| 2048 * 2048 | 4,194,304 | 600 次 |
| 4096 * 4096 | 16,777,216 | 600 次 |
Step 2:效能比較指標(硬體配置)
以下是測試電腦的配置,規格在中階範圍:
| 1. CPU 與核心數 | : | Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz (12 CPUs), ~3.2GHz |
| 2. GPU 與顯示卡 | : | Nvdia GeForce RTX 2060 12G |
| 3. DirectX 版本 | : | DirectX 12 |
| 4. 記憶體 | : | 48 GB |
| 5. 作業系統版本 | : | Windows 10 專業版 64 位元 |
| 6. 運算時間 | : | 每 100 Tric 觸發一次 (每秒10次),並且觸發 600 次就停止 |
| 7. ILGPU 版本 | : | 1.5.2 |
| 8. C# 版本 | : | 8.0 |
補充此規格的研究特點:
| 硬體 | 補充描述 | 評價 |
|---|---|---|
| CPU: i7-8700 (6C/12T) | 第 8 代 Intel CPU 仍為中接 | 中階效能代表,多數開發者機器仍使用同等級 |
| GPU: RTX 2060 (12GB VRAM) | 支援 CUDA Cores 約 2176,對 ILGPU 非常友好 | 中階 GPU,但適合大量平行處理場景 |
| 記憶體: 48GB RAM | 可測試大型 2D 網格(4096 * 4096 綽綽有餘) | 在此次比較效能的過程中,可排除記憶體瓶頸 |
| ILGPU 1.5.2 + DirectX 12 | LGPU 最新穩定版,支援 CUDA / OpenCL | 完整支援 GPU 平行化 |
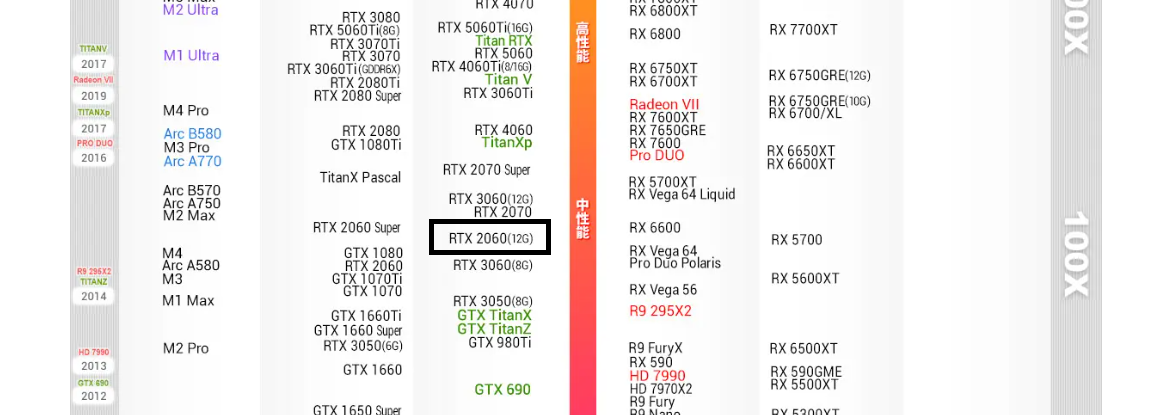
系統資訊圖:


CPU天梯排名中 I7-8700 屬於中階 CPU(放在2025)
GPU 顯卡天梯排名RTX 2060 12G 版本亦屬於中階顯卡(放在2025)
Step 3:執行測試與數據收集
基本測試方針:
| 1. 多次測試 | : | 對每種方法執行至少 5 次測試,取平均值以減少偶然誤差。 |
| 2. 記錄時間 | : | 除了總耗費時間外,還可以記錄每個操作的平均耗時和最大耗時,並且各執行 5 次 |
| 3. 硬體設備 | : | 所有測試都使用相同配備。 |
| 4. 相同次數 | : | 600 次生命週期,每秒最多觸發 10 次 |
第二部分:測試範例代碼
Step 1:CPU 範例代碼
CPU 的代碼,可參考0008. 康威生命遊戲(Game Of Life) - 細胞自動機模擬與程序化生成
調整後的代碼在啟動時會有選項
Step 2:GPU 範例代碼 - 使用 ILGPU
GPU 的代碼也調整於此範例代碼中
在 Nuget 中引用 ILGPU

Step 3:GPU 範例代碼 - 使用方法
專案中的 3-4. 啟動代碼時,會先判斷有無顯卡,若有才允許使用平行運算
並且在 3-5. 步驟時會設定使用 GpuKernel 方法
// 3-4. 初始化 ILGPU
context = Context.CreateDefault();
try
{
// GPU
accelerator = context.CreateCudaAccelerator(0);//電腦沒有顯示卡,此行會報錯
}
catch
{
// CPU
accelerator = context.CreateCPUAccelerator(0);
}
// 3-5. 設定 kernel 方法
kernel = accelerator.LoadAutoGroupedStreamKernel<Index2D, ArrayView2D<byte, Stride2D.DenseX>, ArrayView2D<byte, Stride2D.DenseX>>(GpuKernel);
Step 4:GPU 範例代碼 - GpuKernel 平行運算方法
實際上的 GpuKernel 就是康威生命遊戲的規則
/// <summary>
/// 5. GPU 核心程式 - 康威生命遊戲的規則 與 3-5 , 4-2 相互關聯
/// </summary>
static void GpuKernel(Index2D index, ArrayView2D<byte, Stride2D.DenseX> current, ArrayView2D<byte, Stride2D.DenseX> next)
{
// 5-1. Game of Life 計算
// 備註: xAxis, yAxis 代表細胞座標
// 備註: gridX, gridY 代表鄰居偏移量
int x = index.X;
int y = index.Y;
int width = current.IntExtent.X;
int height = current.IntExtent.Y;
// 5-2. 計算鄰居數量
int count = 0;
for (int yAxis = -1; yAxis <= 1; yAxis++)
{
for (int xAxis = -1; xAxis <= 1; xAxis++)
{
if (xAxis == 0 && yAxis == 0) continue;
// 處理邊界(環繞)
int nx = (x + xAxis + width) % width;
int ny = (y + yAxis + height) % height;
count += current[new Index2D(nx, ny)];
}
}
byte alive = current[index];
// 5-3. Game of Life 規則
if (alive == 1 && (count < 2 || count > 3))
next[index] = 0; // 死亡
else if (alive == 0 && count == 3)
next[index] = 1; // 誕生
else
next[index] = alive; // 保持原狀
}
Step 5:GPU 範例代碼 - GpuKernel 呼叫時機點
在 4-2. 時( Timer 中) 才會真正執行 GPU 的平行運算處理
// 4-2. 執行 kernel - 傳遞 View 給 kernel (在步驟 3-5. 宣告方法)
kernel(new Index2D(WidthCells, HeightCells), bufferCurrent.View, bufferNext.View);
第三部分:執行測試
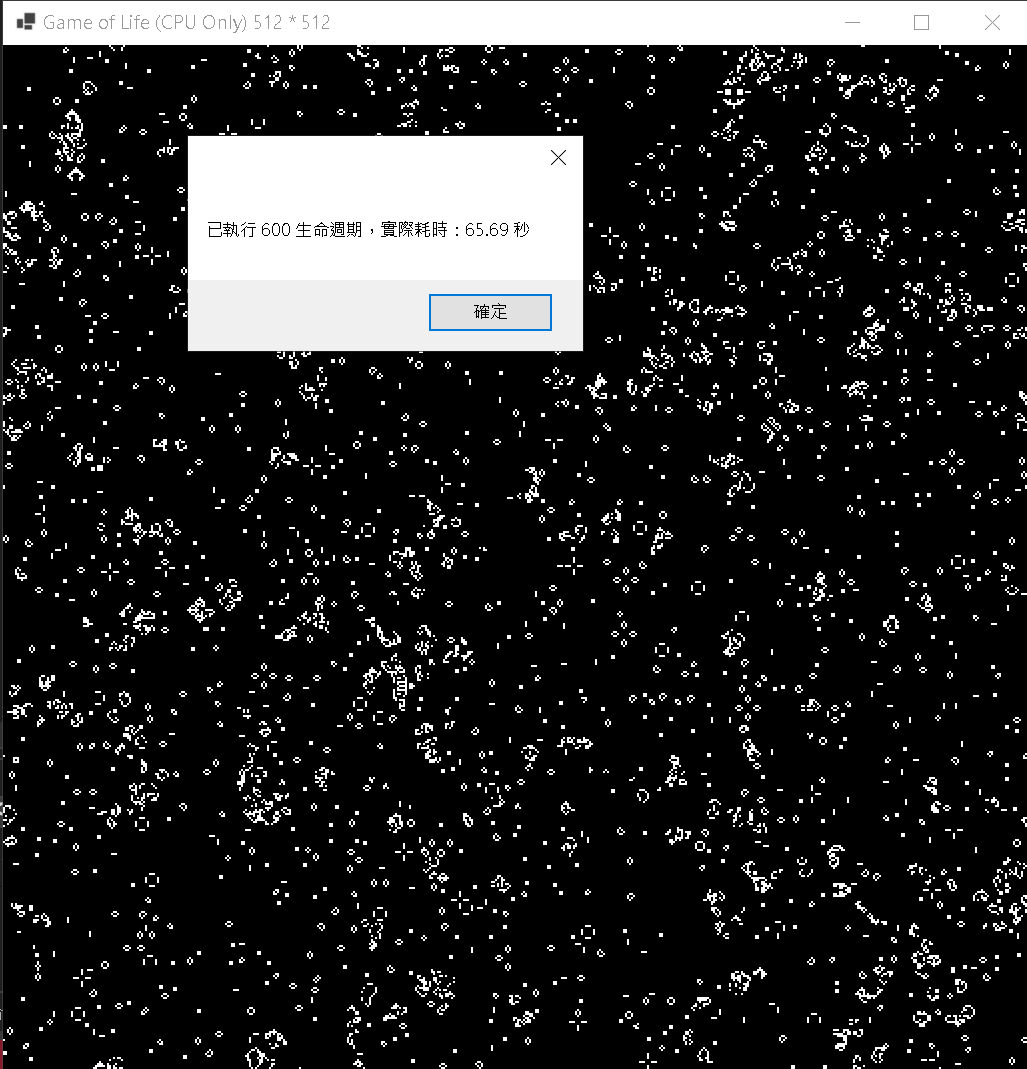
Step 1:執行測試 512 * 512
Cpu 與 GPU 5 次執行結果如下
| 次數 | CPU 測試 | GPU 測試 |
|---|---|---|
| 1. | 耗費:65.69 秒 | 耗費:65.68 秒 |
| 2. | 耗費:65.71 秒 | 耗費:65.72 秒 |
| 3. | 耗費:65.72 秒 | 耗費:65.71 秒 |
| 4. | 耗費:65.73 秒 | 耗費:65.69 秒 |
| 5. | 耗費:65.77 秒 | 耗費:65.68 秒 |
整理最大值、最小值、平均數
| 項目 | CPU 測試 | GPU 測試 |
|---|---|---|
| 最大值 | 65.77 秒 | 65.72 秒 |
| 最小值 | 65.69 秒 | 65.68 秒 |
| 5次平均值 | 65.72 秒 | 65.70 秒 |
擷取自一張 CPU 執行結果圖 512 * 512,其餘略
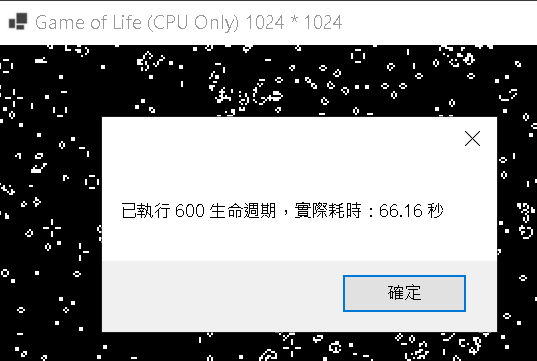
Step 2:執行測試 1024 * 1024
Cpu 與 GPU 5 次執行結果如下
| 次數 | CPU 測試 | GPU 測試 |
|---|---|---|
| 1. | 耗費:65.96 秒 | 耗費:65.68 秒 |
| 2. | 耗費:65.97 秒 | 耗費:65.67 秒 |
| 3. | 耗費:65.80 秒 | 耗費:65.70 秒 |
| 4. | 耗費:66.05 秒 | 耗費:65.72 秒 |
| 5. | 耗費:65.16 秒 | 耗費:65.69 秒 |
整理最大值、最小值、平均數
| 項目 | CPU 測試 | GPU 測試 |
|---|---|---|
| 最大值 | 66.05 秒 | 65.72 秒 |
| 最小值 | 65.16 秒 | 65.67 秒 |
| 5次平均值 | 65.79 秒 | 65.69 秒 |
擷取自一張 CPU 執行結果圖 1024 * 1024,其餘略
Step 3:執行測試 2048 * 2048
Cpu 與 GPU 5 次執行結果如下
| 次數 | CPU 測試 | GPU 測試 |
|---|---|---|
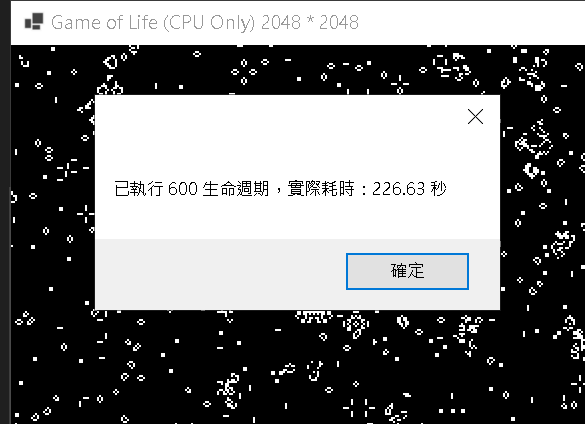
| 1. | 耗費:226.63 秒 | 耗費:74.96 秒 |
| 2. | 耗費:228.07 秒 | 耗費:76.22 秒 |
| 3. | 耗費:232.45 秒 | 耗費:77.91 秒 |
| 4. | 耗費:226.77 秒 | 耗費:73.29 秒 |
| 5. | 耗費:235.81 秒 | 耗費:75.66 秒 |
整理最大值、最小值、平均數
| 項目 | CPU 測試 | GPU 測試 |
|---|---|---|
| 最大值 | 235.81 秒 | 77.91 秒 |
| 最小值 | 226.77 秒 | 73.29 秒 |
| 5次平均值 | 229.95 秒 | 75.61 秒 |
擷取自一張 CPU 執行結果圖 2048 * 2048,其餘略
Step 4:執行測試 4096 * 4096
Cpu 與 GPU 5 次執行結果如下
| 次數 | CPU 測試 | GPU 測試 |
|---|---|---|
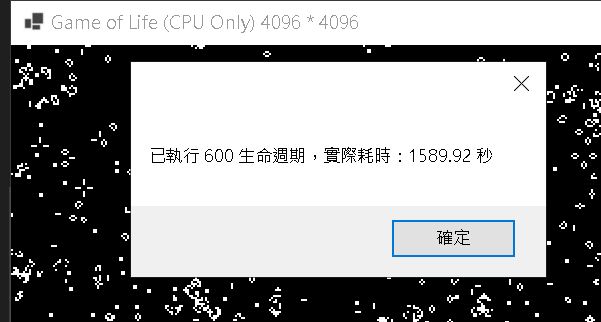
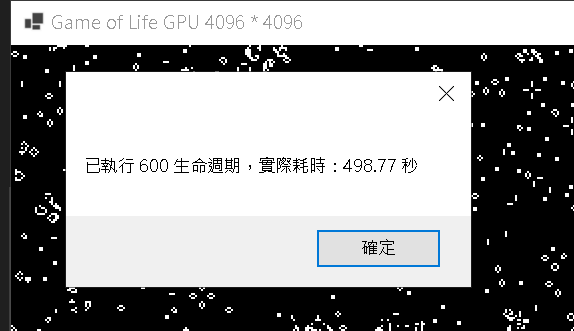
| 1. | 耗費:1,589.92 秒 | 耗費:498.77 秒 |
| 2. | 耗費:1,584.38 秒 | 耗費:502.84 秒 |
| 3. | 耗費:1,572.89 秒 | 耗費:493.25 秒 |
| 4. | 耗費:1,601.44 秒 | 耗費:506.59 秒 |
| 5. | 耗費:1,596.71 秒 | 耗費:495.63 秒 |
整理最大值、最小值、平均數
| 項目 | CPU 測試 | GPU 測試 |
|---|---|---|
| 最大值 | 1,601.44 秒 | 502.84 秒 |
| 最小值 | 1,572.89 秒 | 493.25 秒 |
| 5次平均值 | 1,589.07 秒 | 499.42 秒 |
擷取自一張 CPU 執行結果圖 4096 * 4096,其餘略
擷取自一張 GPU 執行結果圖 4096 * 4096,其餘略
第四部分:分析結果 & 結論
Step 1:重複 5 次執行測試 - 平均耗時
平均時間與補充備註:
| 執行細胞數量 | CPU 5次平均總耗時(秒) | GPU 5次平均總耗時 |
|---|---|---|
| 512 * 512 | 65.72 秒 | 65.70 秒 |
| 1024 * 1024 | 65.79 秒 | 65.69 秒 |
| 2048 * 2048 | 229.95 秒 | 75.61 秒 |
| 4096 * 4096 | 1,589.07 秒 | 499.42 秒 |
Step 2:結論 & 圖表
| GPU 相對於 CPU 的效能比較 |
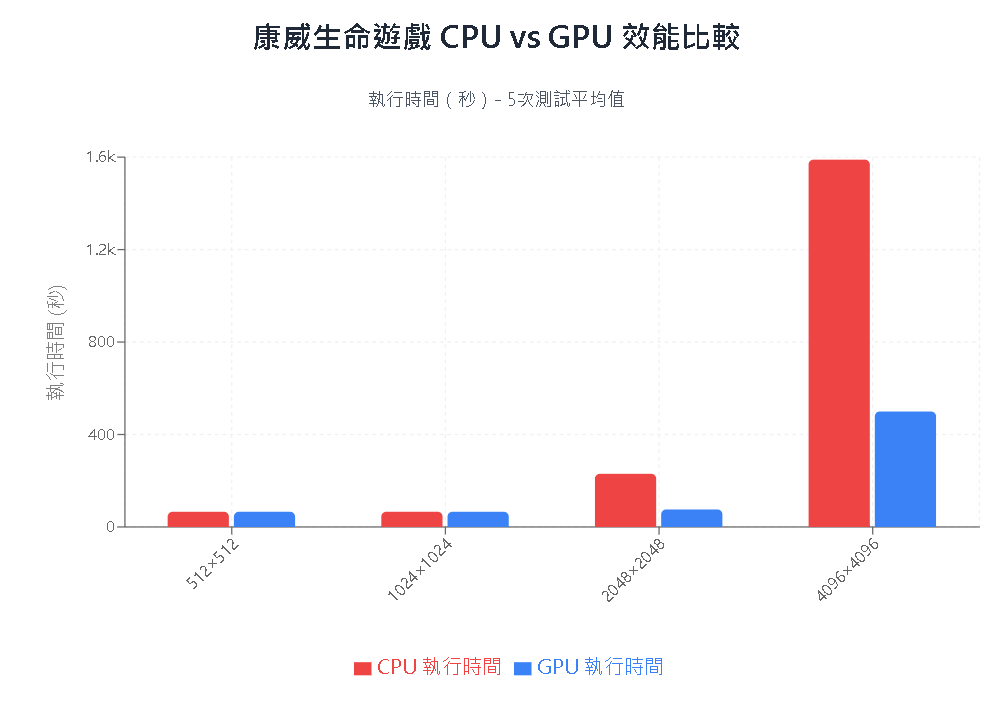
| GPU 相對於 CPU 的效能提升倍數 |
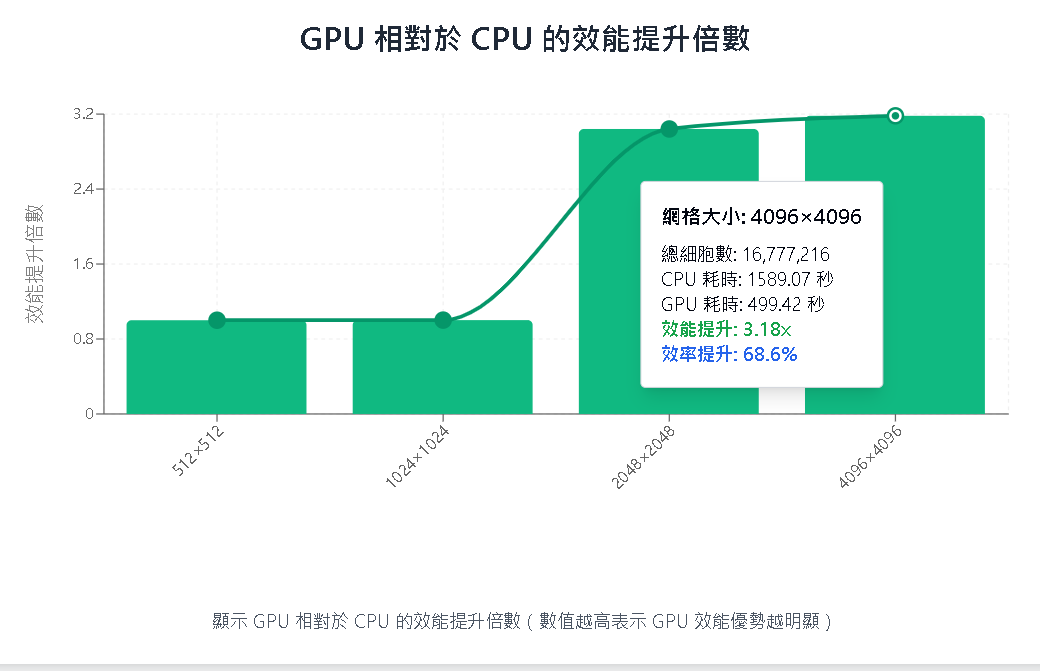
分析與結論:
| 尺寸 | 結論 |
|---|---|
| 小尺寸 512 * 512 與 1024 * 1024 | GPU 優勢不明顯,原因可能是 GPU 啟動與資料傳輸成本抵銷了平行處理帶來的效益。 |
| 中尺寸 2048 * 2048 | GPU 開始展現優勢,速度為 CPU 的約 3 倍以上。 |
| 大尺寸 4096 * 4096 | GPU 表現壓倒性勝出,CPU 花費超過 GPU 三倍以上時間,明顯不適合處理超大型網格。 |