日期:2026年 01月 24日
標籤: Algorithm Cache Algorithm C# Asp.NET Core
摘要:演算法-快取策略
n:設定快取的上限筆數
時間複雜度(Time Complex):O(1) ※ 取值 / 存值
空間複雜度: O(n)
範例檔案:Source Code
範例專案:Code Project
基本介紹:本篇分為4大部分。
第一部分:MRU演算法 - 介紹
第二部分:MRU演算法 - 實現
第三部分:MRU演算法 - 圖解流程
第四部分:補充說明
第一部分:LFU演算法 - 介紹
Step 1:簡介
以下截取於Wiki
Most-recently-used (MRU)
Unlike LRU, MRU discards the most-recently-used items first.
At the 11th VLDB conference, Chou and DeWitt said: "When a file is being repeatedly scanned in a [looping sequential] reference pattern,
MRU is the best replacement algorithm.
簡言之:「最近被使用的資料優先刪除」,最後用到的物件權重最低,用此演算法通常適合應用文檔或多步撤銷系統
※來源:Wiki

Step 2:優缺點
優點具有以下:
| 1. 在「一次性資料」模式下效能很好 | 因為最近用過的資料往往「不會再被重新使用」。 |
| 2. 適合 sequential access(線性掃描資料) | 資料消耗方式為往前不回頭,如影片播放、文件 parsing、流處理。 |
| 3. 不需要保留近期資料的場景中較合適 | 因為舊資料反而優先保留下來。 |
| 4. 在 cache 內容不會回頭重覆使用時佔優 | 假設系統不會再次訪問已看過的內容,MRU 選擇最合理。 |
缺點:
| 1. 不適合資料會重複被使用的情況 | 如果資料可能在未來被再次查詢,MRU 會造成 cache miss。 |
| 2. 對 hot data(熱門資料)非常不友善 | 越熱門 → 越常被使用 → 越最近使用 → 越容易被刪掉 |
| 3. 一般通用系統下效能會差於 LRU | 現實中資料會重複被訪問,而 MRU 反直覺地刪掉近期熱門資料。 |
| 4. 若被頻繁取用的資料恰巧也「最近被使用」,反而最容易被刪掉 | same object → repeatedly fetched → repeatedly evicted → repeatedly reloaded ➜ 明顯降低效能 |
Step 3:應用場景說明
以下列舉生活常見的 MRU Cache 應用,以及補充何種狀況下不合適採用
| 場景 | 適合 MRU 的原因 | 不適用情況 | 實際生活例子 |
|---|---|---|---|
| 1. 大型檔案 Sequential read | 剛取出的資料接下來很少再被用一次 | 若使用者會回頭讀前面段落 | 同一個 PDF 從第 1 頁讀到第 200 頁 |
| 2. 批次資料流處理 | 每筆資料只用一次,之後不再需要 | 資料可能被再次查詢 | log pipeline、ETL 批次處理 |
| 3. 圖片/影片處理流程 | 最近處理的 frame 過了就不會再看 | 使用者會重播特定 frame | 視訊解碼器往後播放每一幀 |
第二部分:MRU演算法 - 實現
Step 1:完整代碼
完整代碼可以從Source Code下載
主要以下 3 個部分完成,整理複雜度 + 完整代碼框架如下:
※關鍵差異 : 刪除的策略是最新的資料優先刪除
| 1. 快取策略容量上限 | 空間複雜度 O(n) | MRU 同 LRU 需要 HashMap + LinkedList,兩者都持有 n 項資料,所以空間 O(n) |
| 2. 取值的處理 | 時間複雜度 O(1) | MRU 同 LRU,HashMap 取得節點 = O(1),再更新鏈結位置 = O(1) |
| 3. 存值的處理 | 時間複雜度 O(1) | MRU 同 LRU,查找、插入/更新、鏈表調整全部都是 O(1) |
public class MostRecentlyUsedAlgorithm
{
public readonly int _capacity;
public readonly Dictionary<string, LinkedListNode<(string key, string value)>> _cache;
public readonly LinkedList<(string key, string value)> _links;
/// <summary>
/// 1. 建構式 - 快取策略容量上限
/// </summary>
public MostRecentlyUsedAlgorithm(int capacity)
{
_capacity = capacity;
_cache = new Dictionary<string, LinkedListNode<(string key, string value)>>();
_links = new LinkedList<(string key, string value)>();
}
/// <summary>
/// 2. 取值的處理 (同 LRU 處理)
/// </summary>
public string Get(string key)
{
}
/// <summary>
/// 3. 存值的處理
/// </summary>
public void Put(string key, string value)
{
}
}
Step 2:1. 快取策略容量上限
MRU 使用時,需決定保存快取上限
與 LRU 完全相同的初始配置
/// <summary>
/// 1. 建構式 - 快取策略容量上限
/// </summary>
public MostRecentlyUsedAlgorithm(int capacity)
{
_capacity = capacity;
_cache = new Dictionary<string, LinkedListNode<(string key, string value)>>();
_links = new LinkedList<(string key, string value)>();
}
Step 3:2. 取值的處理
取值的處理,每當被檢索到時,將權重 降低
/// <summary>
/// 2. 取值的處理 (同 LRU 處理)
/// </summary>
public string Get(string key)
{
if (!_cache.ContainsKey(key))
return string.Empty;
var node = _cache[key];
_links.Remove(node);
_links.AddFirst(node);
return node.Value.value;
}
Step 4:3. 存值的處理
存值的處理,當存入時,有 2 個方向,共 3 種情況,關鍵差異在 刪除
| 是否已存在 | 是否達到設定上限 | 處理方式 |
|---|---|---|
| 存在 | 更新 Key 的 Value 值 並且將權重降到最低 | |
| 不存在 | 是 | 移除權重最低的資料 + 新增 Key 的 Value 值 並且最低權重 |
| 不存在 | 否 | 新增 Key 的 Value 值 並且最低權重 |
/// <summary>
/// 3. 存值的處理
/// </summary>
public void Put(string key, string value)
{
// 3-1. 存在的狀況同 LRU
if (_cache.ContainsKey(key))
{
var node = _cache[key];
_cache.Remove(node.Value.key);
_links.Remove(node);
var newNode = _links.AddFirst((key, value));
_cache[key] = newNode;
}
else
{
// 3-2. [關鍵] MRU 與 LRU 關鍵差異在刪除的快取策略
if (_cache.Count() >= _capacity)
{
// MRU 刪除最近使用的 : 與 FRU 差異在此
var firstNode = _links.First;
_cache.Remove(firstNode.Value.key);
_links.RemoveFirst();
}
var newNode = _links.AddFirst((key, value));
_cache[key] = newNode;
}
}
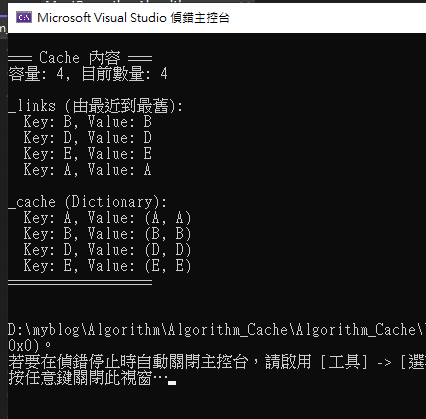
Step 5:DEMO - 成功執行結果
附上代碼執行結果,此結果是與 Wiki 上的範例 & 結果一致
| 依序放入(全是 Put) | A B C D E C D B | | 執行結果(權重低到高) | B D E A |
第三部分:MRU演算法 - 圖解流程
Step 1:初始設定上限
依照 Wiki 的範例對照,我們設定了最大上限為 4,尚未塞入任何資料,初始結構如下:
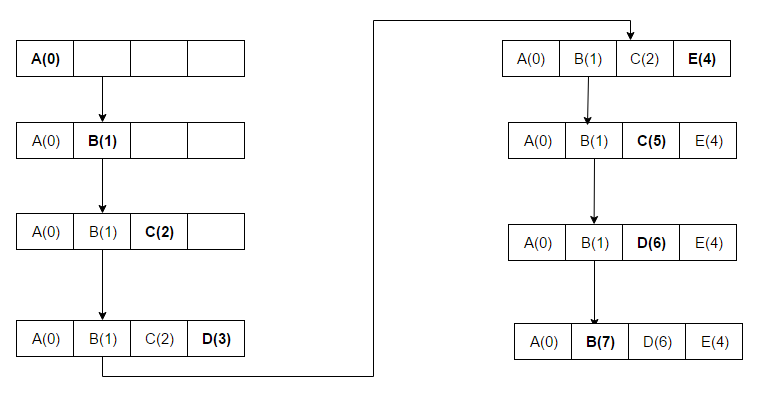
目標依序放入 A B C D E C D B
為了說明清楚,Value 與 Key 都會用相同的英文字母表示
Step 2:新增值 SET - (A, A)
添加值 KEY = A ; Value = A

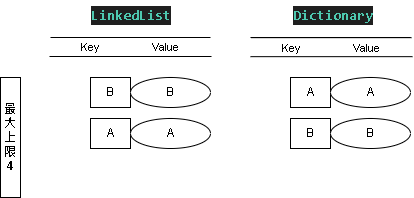
Step 3:新增值 SET - (B, B)
添加值 KEY = B ; Value = B
這時 LinkedList 表的權重最低(優先刪除) B > A
Step 4:新增值 SET - (C, C)
添加值 KEY = C ; Value = C
這時 LinkedList 表的權重最低(優先刪除) C > B > A
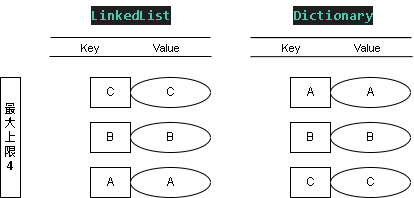
Step 5:新增值 SET - (D, D)
添加值 KEY = D ; Value = D
這時 LinkedList 表的權重最低(優先刪除) D > C > B > A
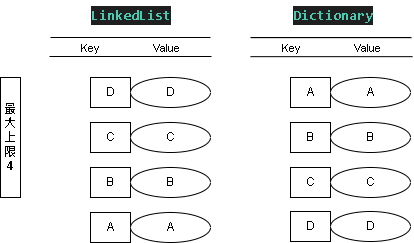
Step 6:新增值 SET - (E, E)
添加值 KEY = E ; Value = E
因為 D 最近使用,權重最低因此被刪除
這時 LinkedList 表的權重最低(優先刪除) E > C > B > A
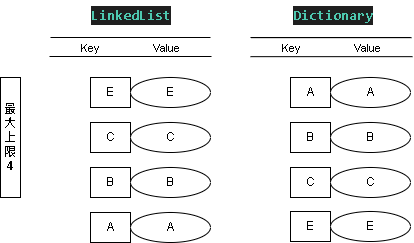
Step 7:新增值 SET - (C, C)
添加值 KEY = C ; Value = C , C 雖然已存在,但仍要刷新權重
這時 LinkedList 表的權重最低(優先刪除) C > E > B > A
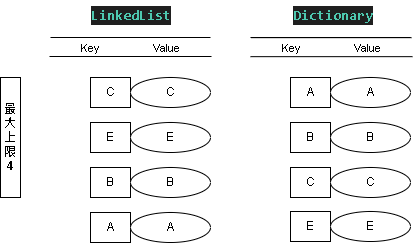
Step 8:新增值 SET - (D, D)
添加值 KEY = D ; Value = D
因為 C 最近使用,權重最低因此被刪除
這時 LinkedList 表的權重最低(優先刪除) D > E > B > A
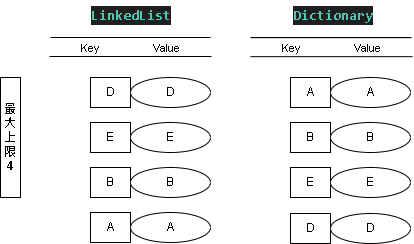
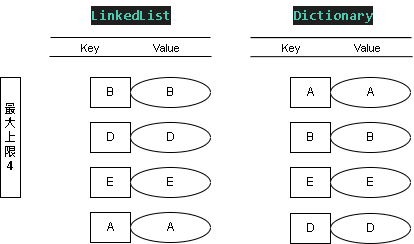
Step 9:新增值 SET - (B, B)
添加值 KEY = B ; Value = B , B 雖然已存在,但仍要刷新權重
這時 LinkedList 表的權重最低(優先刪除) B > D > E > A
最終符合 Wiki 上的 MRU 快取策略
第四部分:補充說明
Step 1:補充 - MRU 與 Stack 實質上的不同
Stack 是資料結構,MRU 則是一種快取策略,雖然看似都有 FIFO ,但實質上是不同的事情:
| MRU | Stack |
|---|---|
| 是快取淘汰策略 | 是資料結構 |
| 決定刪除誰 | 決定資料放置順序 |
| 有全局容量概念 | 無容量策略 |
| 有使用時間語意 | 只有順序語意 |
| 可以用其他結構實現(不一定是 stack) | 不一定用於快取 |
總結:
Stack 能表達的是「順序」
MRU 能表達的是「使用頻率與時間意義」
Step 2:補充 - LRU 與 MRU 對比
MRU 是 LRU 的變體,實務上 MRU 都是與其他策略算法進行合併使用,即使是瀏覽器的 上一頁 功能,也不是 100% MRU 相同,也是需要搭配業務需求進行變化。
※補充瀏覽器 上一頁 意思: 壓著後列出有序的訪問網頁清單,並且點擊最上層會移除,但是選擇其他的選項會移除在此之上的訪問節點,並且有上限(很類似 MRU)
| 特色 | LRU | MRU |
|---|---|---|
| 淘汰邏輯 | 刪掉最久沒被用的 | 刪掉最近才被用的 |
| 假設模式 | 過去近期使用 → 未來也可能使用 | 剛用過 → 未來可能不會再用 |
| 表現最佳情況 | 重複訪問同一批資料 | 大量一次性資料、順序性掃描 |
| 表現較差情況 | 大量 sequential access | 熱點資料(hot data)頻繁重用 |