日期:2026年 01月 03日
標籤: Algorithm Cache Algorithm C# Asp.NET Core
摘要:演算法-快取策略
n:設定快取的上限筆數
時間複雜度(Time Complex):O(1) ※ 取值 / 存值
空間複雜度: O(n)
範例檔案:Source Code
範例專案:Code Project
基本介紹:本篇分為3大部分。
第一部分:LRU演算法 - 介紹
第二部分:LRU演算法 - 實現
第三部分:LRU演算法 - 圖解流程
第一部分:LRU演算法 - 介紹
Step 1:簡介
以下截取於Wiki
Least Recently Used (LRU)
Discards least recently used items first. This algorithm requires keeping track of what was used and when, which is cumbersome. It requires "age bits" for cache lines, and tracks the least recently used cache line based on these age bits. When a cache line is used, the age of the other cache lines changes.
簡言之:「把最近使用的資料移到前面」,確保最近常被用到的物件不會被淘汰,用此演算法通常適合應用於網路的分散式快取,捨棄那些不常訪問、使用的資料
※來源:Wiki

Step 2:優缺點
優點具有以下:
| 1. 提升快取命中率 | 保留最近使用的資料,符合真實應用的時間局部性,提高 hit rate。 |
| 2. O(1) 高效操作 | 使用 HashMap + Doubly Linked List 可達到 O(1) 查詢、更新、淘汰。 |
| 3. 適用高併發環境 | Redis、Memcached、OS Page Cache、CPU Cache 等多採用 LRU 概念。 |
| 4. 行為可預期 | 淘汰邏輯明確:最久沒被使用的資料優先移除。 |
缺點:
| 1. 維護成本較高 | 每次 Get/Put 都需移動鏈表節點,較 FIFO / Random 有額外負擔。 |
| 2. 隨機存取表現不佳 | 若沒有局部性(如隨機 workload),LRU 效果差且維護成本浪費。 |
| 3. 容易受一次性大量資料干擾 | 大型掃描等操作可使快取被快速「洗掉」,稱為 Cache Pollution。 |
| 4. 分散式無法維持全局 LRU | 在 Redis Cluster 等架構中,LRU 僅限於節點內部,不是全系統級。 |
Step 3:應用場景說明
以下列舉生活常見的 LRU Cache 應用,以及補充何種狀況下不合適採用
| 場景 | 適合 LRU 的原因 | 不適用情況 |
|---|---|---|
| 1. Web API 回應快取 | 熱門資料反覆被查詢,符合時間局部性 | 隨機或低重複查詢的 API |
| 2. DB 查詢快取 | 查詢成本高,最近查詢很可能再次使用 | 大量分散且無重複查詢的情況 |
| 3. Redis/Memcached | Redis 內建 LRU,與常見 Web pattern 契合 | 分散式下無法維持全局 LRU |
| 4. OS Page Cache | 程式存取具有局部性 | 大型 sequential scan(如 DB 全表掃描) |
| 5. CPU Cache | 迴圈、函式呼叫都符合局部性 | 大量隨機 memory access |
| 6. 檔案系統 Cache | 常用檔案重複被讀 | 大檔案 streaming |
| 7. Browser Tab/Session | 最近用過的 Tab/Session 通常會再用 | 超大量 Tab 短暫性開關 |
第二部分:LRU演算法 - 實現
Step 1:完整代碼
完整代碼可以從Source Code下載,此代碼對應於 LeetCode 的 146 題,LRU Cache
主要以下 3 個部分完成,整理複雜度 + 完整代碼框架如下:
※關鍵作法 : Dictionary + LinkedListNode + LinkedList 處理
| 1. 快取策略容量上限 | 空間複雜度 O(n) | LRU 需要 HashMap + LinkedList,兩者都持有 n 項資料,所以空間 O(n) |
| 2. 取值的處理 | 時間複雜度 O(1) | HashMap 取得節點 = O(1),再更新鏈結位置 = O(1) |
| 3. 存值的處理 | 時間複雜度 O(1) | 查找、插入/更新、鏈表調整全部都是 O(1) |
public class LRUCache
{
private readonly int _capacity;
private readonly Dictionary<int, LinkedListNode<(int key, int value)>> _cache;
private readonly LinkedList<(int key, int value)> _links;
/// <summary>
/// 1. 建構式 - 快取策略容量上限
/// </summary>
public LRUCache(int capacity)
{
}
/// <summary>
/// 2. 取值的處理
/// </summary>
public int Get(int key)
{
}
/// <summary>
/// 3. 存值的處理
/// </summary>
public void Put(int key, int value)
{
}
}
Step 2:1. 快取策略容量上限
LRU 使用時,需要決定可保存快取的上限,結合 LeetCode 以建構式的方式賦值
/// <summary>
/// 1. 建構式 - 快取策略容量上限
/// </summary>
public LRUCache(int capacity)
{
_capacity = capacity;//1-2. 記錄 LRU 快取上限
_links = new LinkedList<(int key, int value)>();
_cache = new Dictionary<int, LinkedListNode<(int key, int value)>>();
}
Step 3:2. 取值的處理
取值的處理,每當被檢索到時,將權重更新到最高
/// <summary>
/// 2. 取值的處理
/// </summary>
public int Get(int key)
{
if (!_cache.ContainsKey(key))
{
//2-1. 不存在返回 -1
return -1;
}
var node = _cache[key];//2-2. 存在時,將權重放到最前面
_links.Remove(node);// 2-3. 移除舊的位置
_links.AddFirst(node);// 2-4. 放在最前面
return _cache[key].Value.value;// 2-5. 返回結果
}
Step 4:3. 存值的處理
存值的處理,當存入時,有 2 個方向,共 3 種情況
| 是否已存在 | 是否達到設定上限 | 處理方式 |
|---|---|---|
| 存在 | 更新 Key 的 Value 值 並且將權重往前(最高權重) | |
| 不存在 | 是 | 移除最舊的資料 + 新增 Key 的 Value 值 並且將權重往前(最高權重) |
| 不存在 | 否 | 新增 Key 的 Value 值 並且將權重往前(最高權重) |
/// <summary>
/// 3. 存值的處理
/// </summary>
public void Put(int key, int value)
{
// 3-1. 是否存在
if (_cache.TryGetValue(key, out LinkedListNode<(int key, int value)>? node))
{
// 3-2. 存在時,將權重放到最前面,同個 Key 可能 Value 已經不同
node.Value = (key, value);
_links.Remove(node);// 3-2. 權重往前
_links.AddFirst(node);
}
else
{
//4. 不存在 Key 且 快取額度達到上限
if (_capacity == _cache.Count())
{
//4-1. 移除最後一個資料
var lastNode = _links.Last;
_cache.Remove(lastNode.Value.key);
_links.RemoveLast();
}
// 4-2. 新增資料,設定權重最上面
var newNode = _links.AddFirst((key, value));
_cache[key] = newNode;
}
}
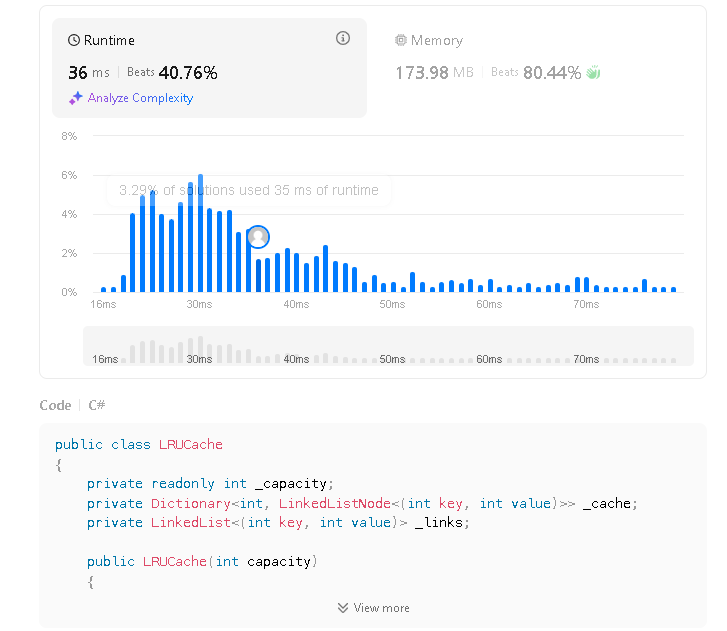
Step 7:LeetCode - 成功執行結果
附上此代碼確實可在 LeetCode 上執行 C# 版本
| Runtime 範圍 | 29 ms ~ 36 ms |
| Runtime Best Beat | 71.73% |
| Memory 範圍 | 171.4 MB ~ 175.3 MB |
| Memory Best Beat | 96.88% |
第三部分:LRU演算法 - 圖解流程
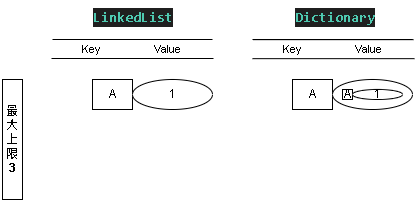
Step 1:初始設定上限
我們設定了最大上限為 3 ,尚未塞入任何資料,初始結構如下:

Step 2:新增值 SET - (A, 1)
添加值 KEY = A ; Value = 1
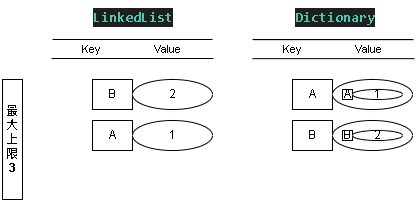
Step 3:新增值 SET - (B, 2)
添加值 KEY = B ; Value = 2
這時 LinkedList 表的優先級 B > A
Step 4:新增值 SET - (C, 3)
添加值 KEY = C ; Value = 3
這時 LinkedList 表的優先級 C > B > A
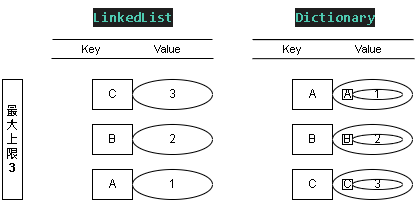
Step 5:取得值 GET - B
查詢 KEY = B ; 因為有存在此 Key 所以得到 2 的值,並且更新權重
這時 LinkedList 表的優先級 B > C > A
※不存在則忽略,LeetCode 返回 -1
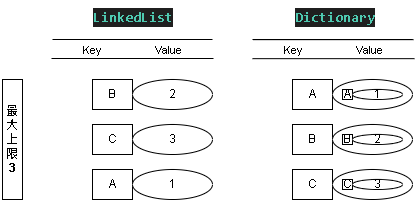
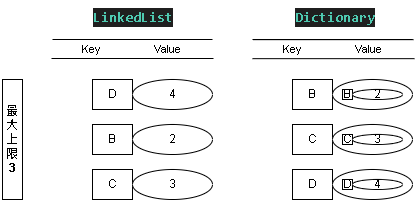
Step 6:新增值 SET - (D, 4)
添加值 KEY = D ; Value = 4
這時 LinkedList 表的優先級 D > B > C
因為上限為 3 ,會讓 最不常使用 的 KEY = A 徹底從緩存移除