日期:2025年 05月 03日
標籤: Linux Ubuntu Docker Docker-Compose Container Grafana Prometheus Node Exporter
摘要:資訊筆記
應用所需:1. Linux 主機(本篇 Linux Ubuntu 22.04 作業系統)
2. 已安裝 Docker
3. 已安裝 Dotnet SDK 8.0 以上版本(本篇範例使用)
解決問題:1. 如何在 Ubuntu 上容器化搭建資料視覺化和監控平台套件
2. 如何設定 Prometheus 做為資料源,進行監控
3. 介紹 Prometheus、Node Exporter (監控機器資源必需的套件)
基本介紹:本篇分為 4 大部分。
第一部分:介紹監控 Grafana
第二部分:介紹相依套件 Prometheus
第三部分:介紹相依套件 Node Exporter
第四部分:安裝 Grafana & DEMO監控機器資源
第一部分:介紹 Grafana
Step 1:介紹
Grafana中文官網
查询、可视化和理解数据,并获取数据警报,无论数据存储在何处。
在 Grafana,您可以通过美观、灵活的数据面板创建、探索和共享所有数据。
簡單說:Grafana 的強大在於跟任何數據來源都能很好的支援,只負責獲取資料,呈現視覺化的圖表。
Step 2:收費價格
付費方案分成 Grafana OSS(開源免費)、Grafana Enterprise(企業付費版)
| Grafana OSS | Grafana Enterprise | |
|---|---|---|
| 可視化與監控 | 核心儀表板功能 | 相同,並有額外優化 |
| 數據來源支援 | 支援 Prometheus, Loki, InfluxDB, Elasticsearch 等 | 企業級數據來源(如 Splunk …) |
| 用戶權限管理 | 只有基本角色(Admin/Editor/Viewer) | 有,更進階 |
| SSO / LDAP 整合 | 需手動設定 | 建 SSO(Google SSO 等) |
| 報告功能 | 沒有 | 內建 PDF / CSV 報告排程 |
| 日誌 | 沒有 | 追蹤使用者行為 |
| 儀表板快取 | 沒有 | 有、效能好 |
| 技術支援 | 論壇、GitHub | 企業級技術支援(SLA 保障) |
| 價格 | 免費 | 可參考官網報價(極貴) |
以上是兩者的差異,如果是小型專案免費版基本上夠用,如果是大型企業才會有需要考慮更高效能的監控、報告
官網報價
Step 3:免費版開源配置限制
官網安裝指南資訊,有建議安裝需求:
以下是最低限制:
Hardware recommendations
Grafana requires the minimum system resources:
Minimum recommended memory: 512 MB
Minimum recommended CPU: 1 core
Some features might require more memory or CPUs, including:
| 1. 記憶體 512 MB |
| 2. 最小 CPU 1 核心 |
Grafana 的強大之處就在於只是收集資料的中繼點,耗費效能的事情都是資料來源的伺服器要煩惱的事情。
Step 4:支援的資料來源與查詢對應
以下是 Grafana 常見的 資料來源、對應的插件,以及主要用途:
| 資料來源 | 插件類型 | 主要用途 |
|---|---|---|
| Prometheus | 官方 | 監控指標數據(Metrics),適用於基礎架構、Kubernetes、應用程式監控 |
| InfluxDB | 官方 | 時序數據(Time-Series Data),可用於 IoT、系統監控 |
| Loki | 官方 | 日誌(Logs),與 Prometheus 互補,用於日誌管理 |
| Elasticsearch | 官方 | 全文檢索 & 日誌數據,適合 Log 監控、APM(應用程式效能管理) |
| Graphite | 官方 | 時序數據分析,與 Prometheus 類似,常用於監控 |
| MySQL / PostgreSQL | 官方 | 關聯式數據庫查詢,可視覺化 SQL 查詢結果 |
| MSSQL | 官方 | 適用於企業的 SQL Server 監控 |
| Azure Monitor | 官方 | 監控 Azure 雲端資源,如 VM、應用服務 |
| Google Cloud Monitoring | 官方 | 監控 GCP(Google Cloud Platform)資源 |
| AWS CloudWatch | 官方 | 監控 AWS 資源,如 EC2、Lambda、RDS |
| OpenTelemetry | 官方 | APM 追蹤數據,與 Jaeger / Zipkin 相似 |
| Jaeger | 官方 | 分佈式追蹤(Tracing),用於 APM(Application Performance Monitoring) |
| Zipkin | 官方 | 另一種分佈式追蹤方案,與 Jaeger 競爭 |
| Splunk | 官方 | 日誌與安全監控(SIEM),企業級方案 |
| Datadog | 官方 | 監控指標與日誌,適用於 Datadog 用戶 |
| New Relic | 官方 | APM & 監控應用程式效能 |
| Snowflake | 官方 | 雲端數據分析,適用於大數據查詢 |
| MongoDB | 社群 | 監控 MongoDB 的查詢效能與指標 |
| Zabbix | 社群 | 整合 Zabbix 監控系統 |
| Ceph | 社群 | 監控 Ceph 分佈式存儲 |
| Redis | 社群 | 監控 Redis 記憶體、查詢效能 |
| RabbitMQ | 社群 | 監控訊息佇列(MQ)狀態 |
| Kafka | 社群 | 監控 Kafka 訊息流與 Broker 狀態 |
| ClickHouse | 社群 | 查詢 ClickHouse 的 OLAP 數據 |
Step 5:Grafana 架構
目標 : 可以透過 Grafana 監控機器的 CPU,記憶體資源,因此整體的架構如圖:
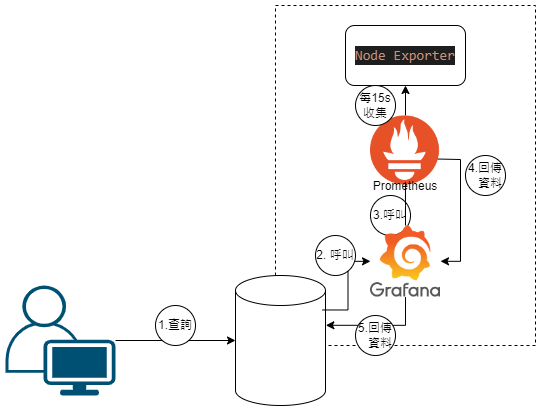
對應圖片,由用戶發起查詢有以下對應流程:
| 1. 用戶進行查詢 |
| 2. 機器收到後呼叫 Grafana 服務 |
| 3. Grafana 服務收到後呼叫 Prometheus |
| 4. Prometheus 服務收到後將紀錄資料回傳給 Grafana |
| 5. 最終用戶可以看到查詢的結果 |
其中 Prometheus 會持續向 Node Exporter 索取資料,來進行紀錄
第二部分:介紹相依套件 Prometheus
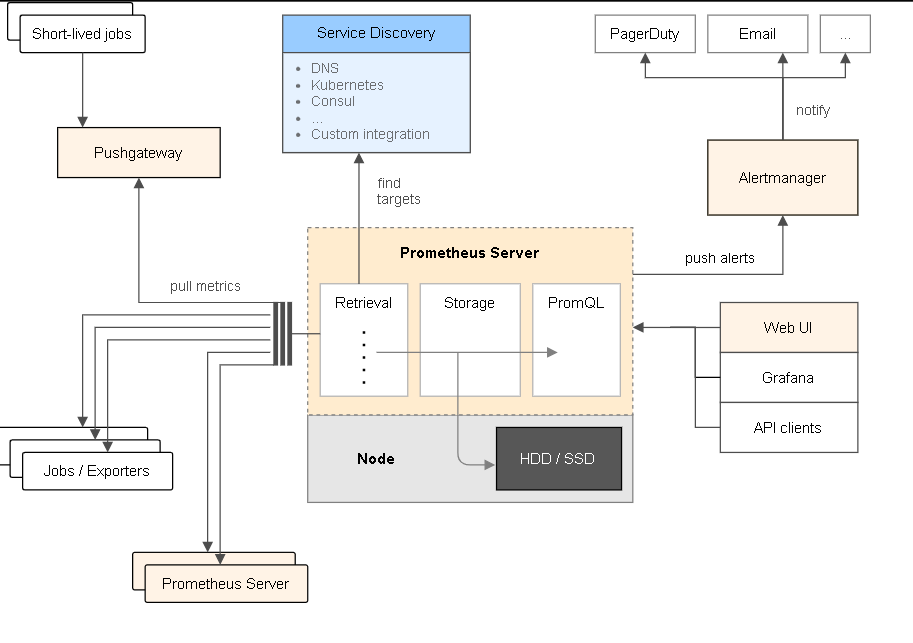
Step 1:介紹 - 主要用途
以下擷取自 Prometheus 的 Github
Prometheus, a Cloud Native Computing Foundation project, is a systems and service monitoring system. It collects metrics from configured targets at given intervals, evaluates rule expressions, displays the results, and can trigger alerts when specified conditions are observed.
大意是說:提供了雲、系統監控、每個時序中收集數據。並且提供依照過濾條件顯示特定的資訊。
※定期抓取數據 & 存儲(可查詢歷史趨勢)
如同資料收集的中樞,有需要的時候可以跟 Prometheus 調閱資料
圖片來源
{kind=link}
Step 2:強大且免費 - 優劣分析
其中 Node Exporter 是 Prometheus 中的一個收集數據套件,但仍可以獨立運行
優點如下:
| 1. 完全開源 & 免費 |
| 2. 時間序列數據高效能 |
| 3. 警告管理自定義 |
| 4. Grafana 無縫整合 |
| 5. 可水平擴展,適合微服務 |
缺點如下:
| 1. 沒有內建長期存儲 |
| 2. 只適合數值型監控 |
| 3. 單機性能有限 |
| 4. 存儲空間需求較大 |
第三部分:介紹相依套件 Node Exporter
Step 1:介紹 - 資源
Node Exporter 與 Prometheus 高度整合的套件,通常兩者會一起使用
Node Exporter指南官方提供安裝操作流程,本篇整合在 docker-compose.yml 中 ,具體也可參考Github
Step 2:介紹 - 主要用途
Node Exporter 是為了視覺化 Prometheus 的資料,顯示系統指標的圖示,特色如下:
| 1. 免費 & 開源 |
| 2. 輕量 & 高效 |
| 3. 監控系統資源指標 |
如果只安裝 Node Exporter 會即刻回傳當前機器系統資源的資料,但無法回顧歷史資料(歷史資料在 Prometheus )
第四部分:安裝 Grafana & DEMO監控機器資源
Step 1:建立 DockerCompose
先進入 Ubuntu 主機上,新建以下 DockerCompose.yml 檔案,內容如下:
version: '3'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
restart: unless-stopped
volumes:
- ./prometheus:/etc/prometheus
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/etc/prometheus/console_libraries'
- '--web.console.templates=/etc/prometheus/consoles'
- '--web.enable-lifecycle'
ports:
- "9200:9090" # 外部使用 9200 連接到內部的 9090
networks:
- grafana-net
node-exporter:
image: prom/node-exporter
container_name: node-exporter
restart: unless-stopped
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- '--path.rootfs=/rootfs'
- '--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|host|etc)($$|/)'
ports:
- "9201:9100" # 外部使用 9201 連接到內部的 9100
networks:
- grafana-net
grafana:
image: grafana/grafana
container_name: grafana
restart: unless-stopped
volumes:
- grafana_data:/var/lib/grafana
ports:
- "9202:3000" # 外部使用 9202 連接到內部的 3000
networks:
- grafana-net
depends_on:
- prometheus
volumes:
prometheus_data:
grafana_data:
networks:
grafana-net:
為了說明,Port 有自定義,對應如下:
| Prometheus | 9200 |
| Node Exporter | 9201 |
| Grafana | 9202 |

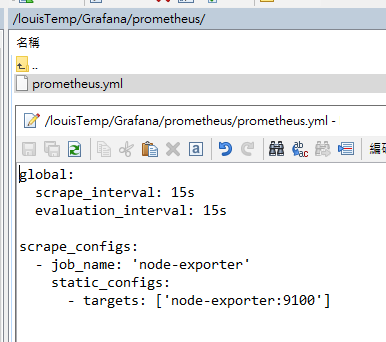
Step 2:建立 prometheus 設定檔案
接著在 Ubuntu 上建立 Prometheus 的配置檔案,要與 Node Exporter 取得資料
這邊 Node Exporter 用 9100 是對應的 Container 內部的 Port 號,而非宿主機的 9201
便於容器內網路相互溝通
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'node-exporter'
static_configs:
- targets: ['node-exporter:9100']
在對應的位置貼上 Container 綁定的 Volumn
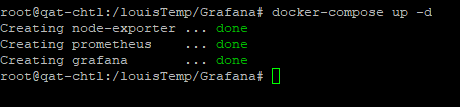
Step 3:啟動 Docker-Compose
在對應目錄上執行 docker-compose.yml 檔案進行安裝
該範例對應 *\louistemp\grafana* 目錄
docker docker-compose.yml -u -p
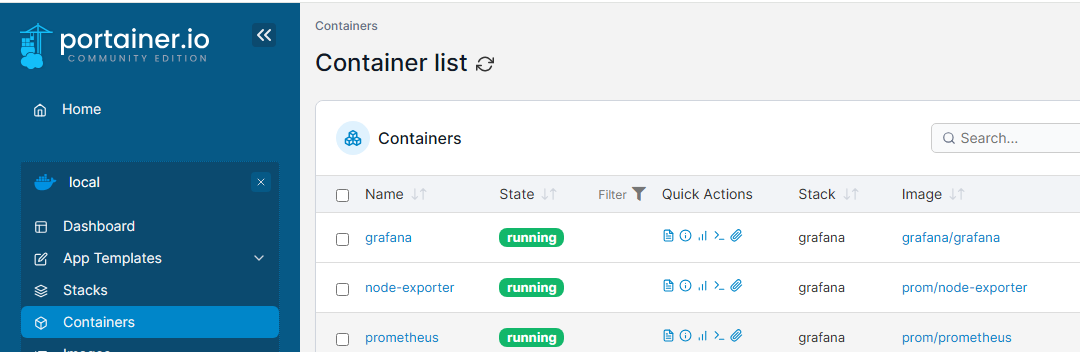
Step 4:檢查容器運行狀況
正常運行後,可以執行以下,或進入 Portainer 觀察容器運行
docker ps -a
Step 5:進入 Grafana WebUI
接著開啟瀏覽器,登入 Grafana 容器提供的 Web URL
http://192.168.1.100:9202/Login
帳號密碼預設為 : admin
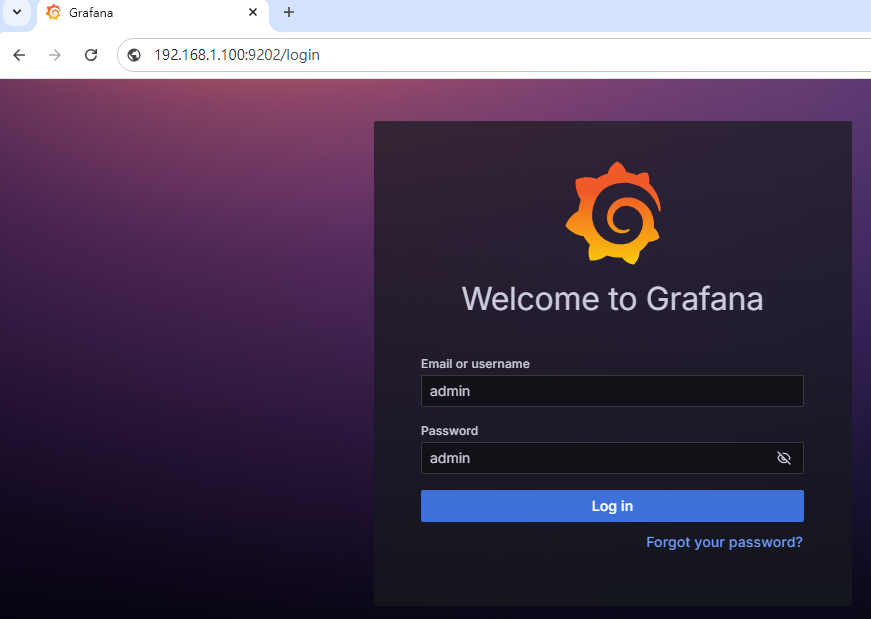
Step 6:配置 Prometheus 為資料來源
要可視覺化 CPU, 記憶體 硬體配置運行資源,需要以 Prometheus 做為資料來源
左側 Menu -> Connections -> Data Source
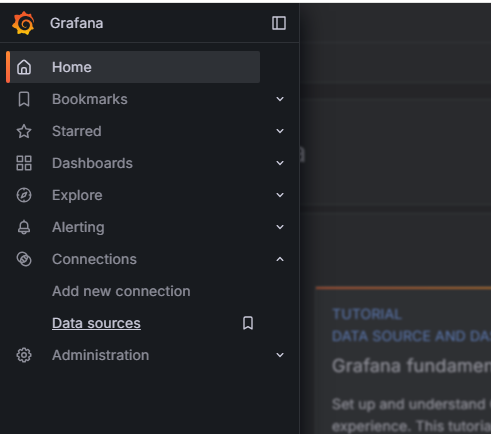
Step 7:配置 Prometheus 為資料來源 - 增加來源
點開後,執行中間的按鈕 -> Add Data Source
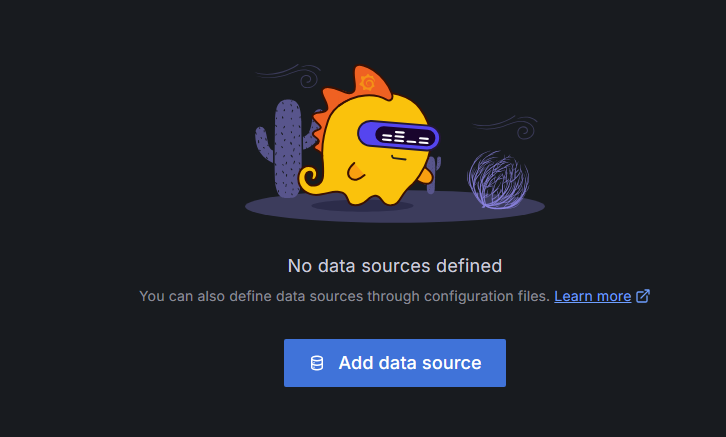
Step 8:配置 Prometheus 為資料來源 - 選擇
選擇 Prometheus 當來源
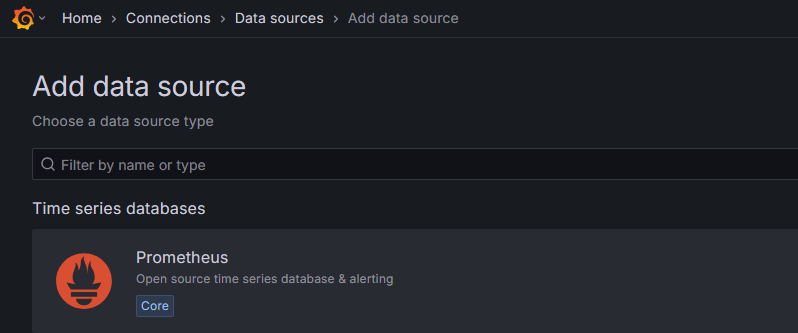
Step 9:配置 Prometheus 為資料來源 - 配置 API 位置
為了讓 Grafana 可以得到 Prometheus 的資料,因此要讓 Grafana 訪問 Prometheus 的 API
在 Connection 的地方輸入對應的 API URL
http://192.168.1.100/
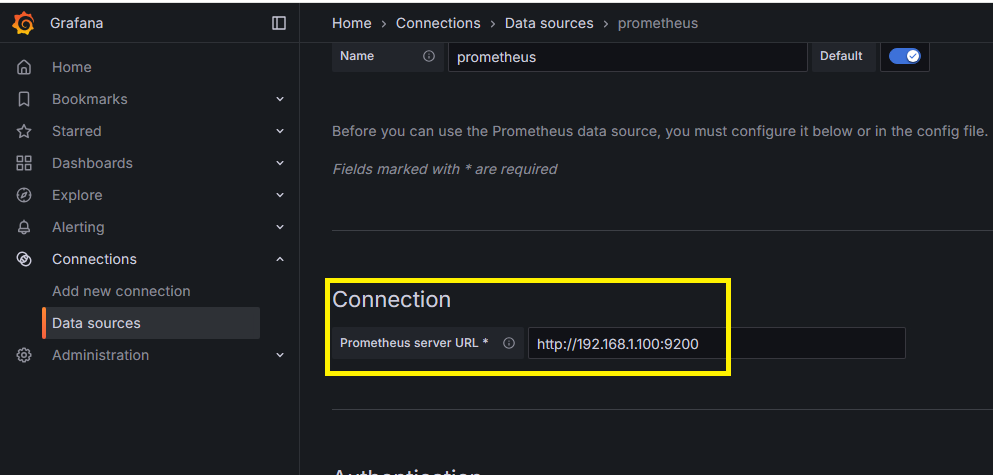
Step 10:配置 Prometheus 為資料來源 - 測試配置
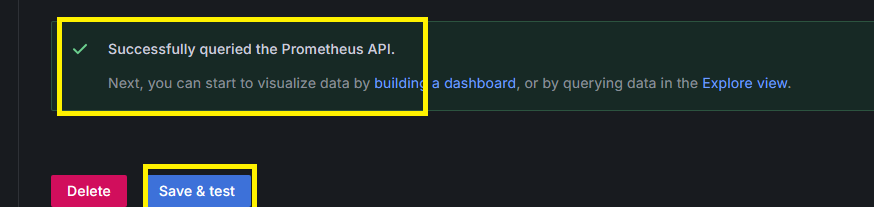
拉到最下方,點擊按鈕 Save & Test,成功的話會出現 Successfuly … 的訊息
資料來源有了後,就可以透過 Prometheus 查詢歷史資料
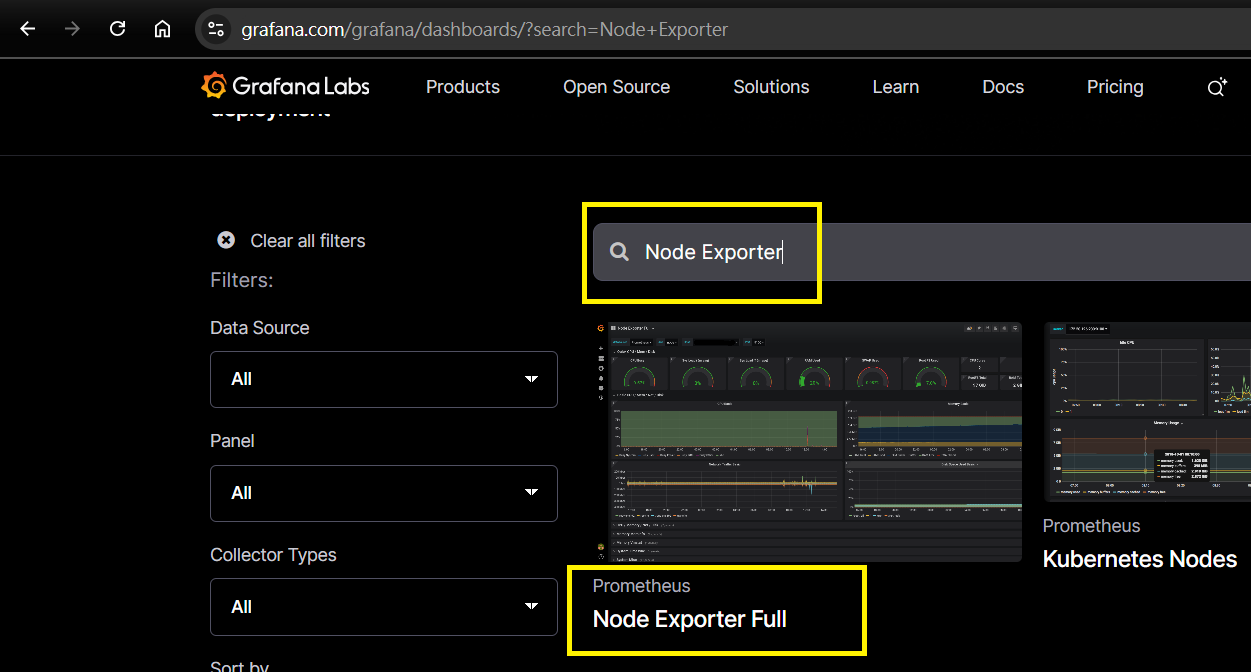
Step 12:確定 Node Exporter 的 ID - 查詢 ID
可以進入 Grafana 官網的 DashBoard 套件查詢
輸入 Node Exporter -> 查詢
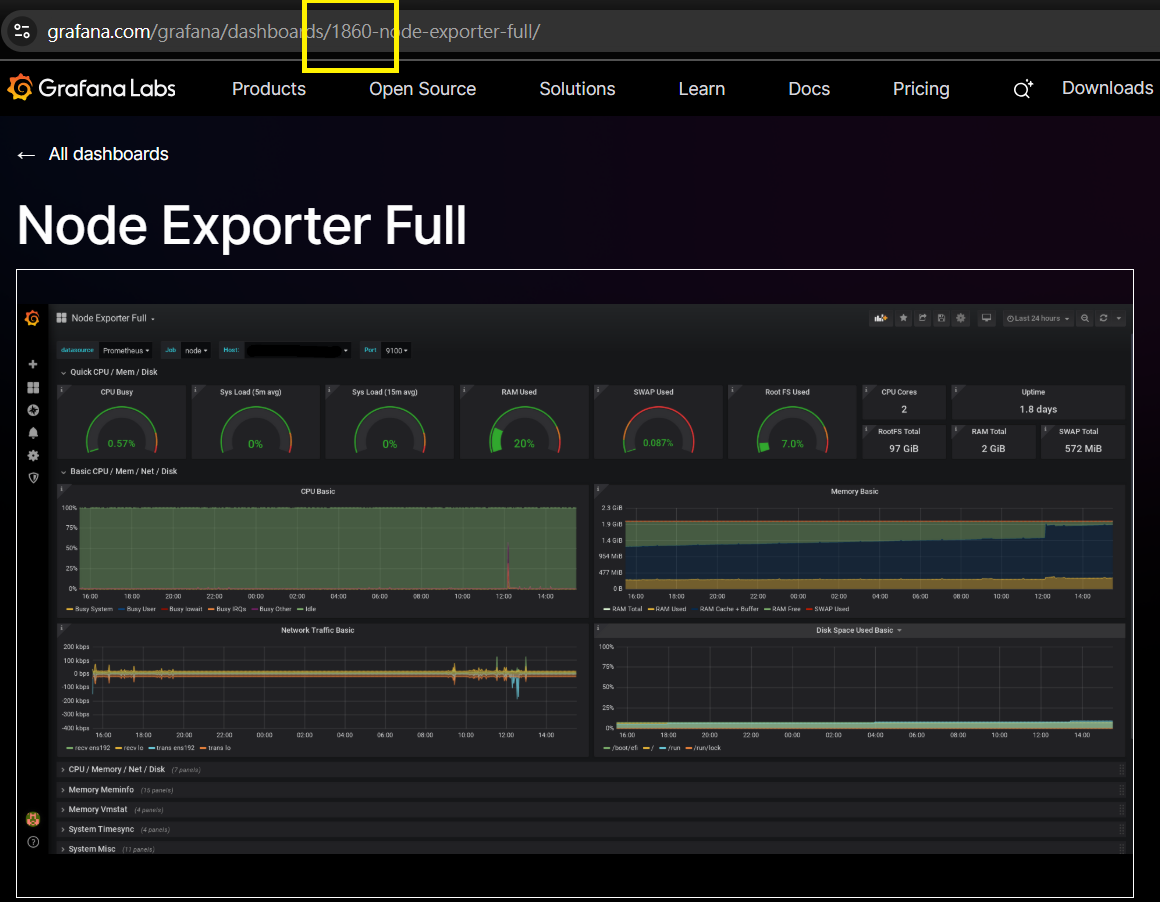
Step 13:確定 Node Exporter 的 ID - 取得 ID
可以在 URL 看到 ID 號碼
Step 14:Grafana儀錶板 - 配置 Node Exporter - 匯入
為了要能在 Grafana 儀表版看到視覺化資料,需要在 DashBoard Import Node Exporter,依序選擇

Step 15:Grafana儀錶板 - 配置 Node Exporter - 匯入設定
將 Step 13. 獲得的 Node Exporter ID輸入
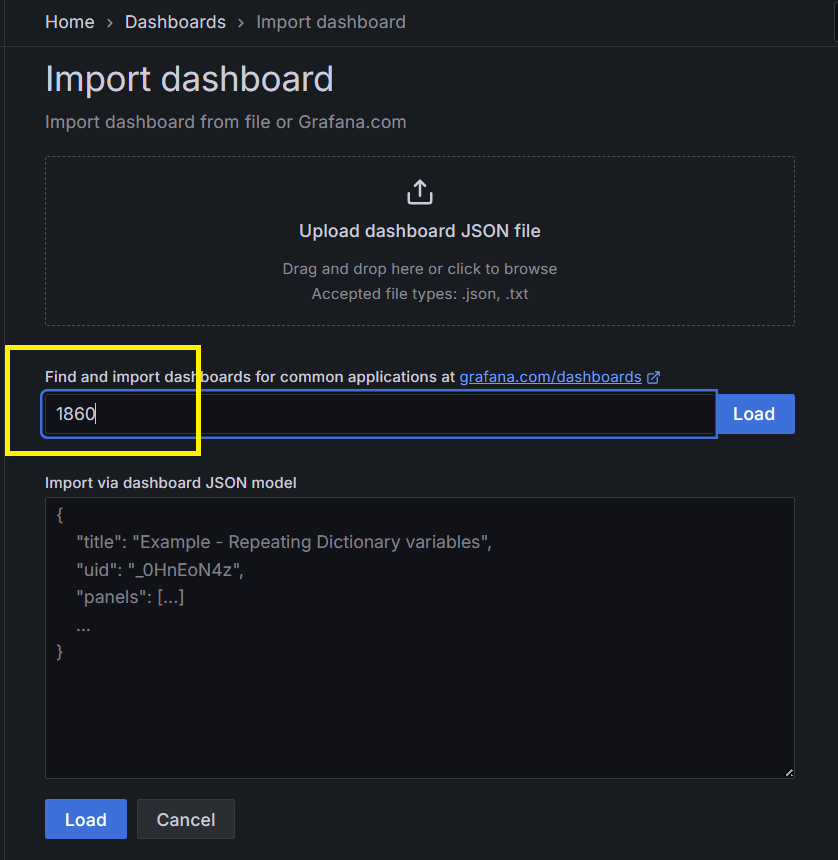
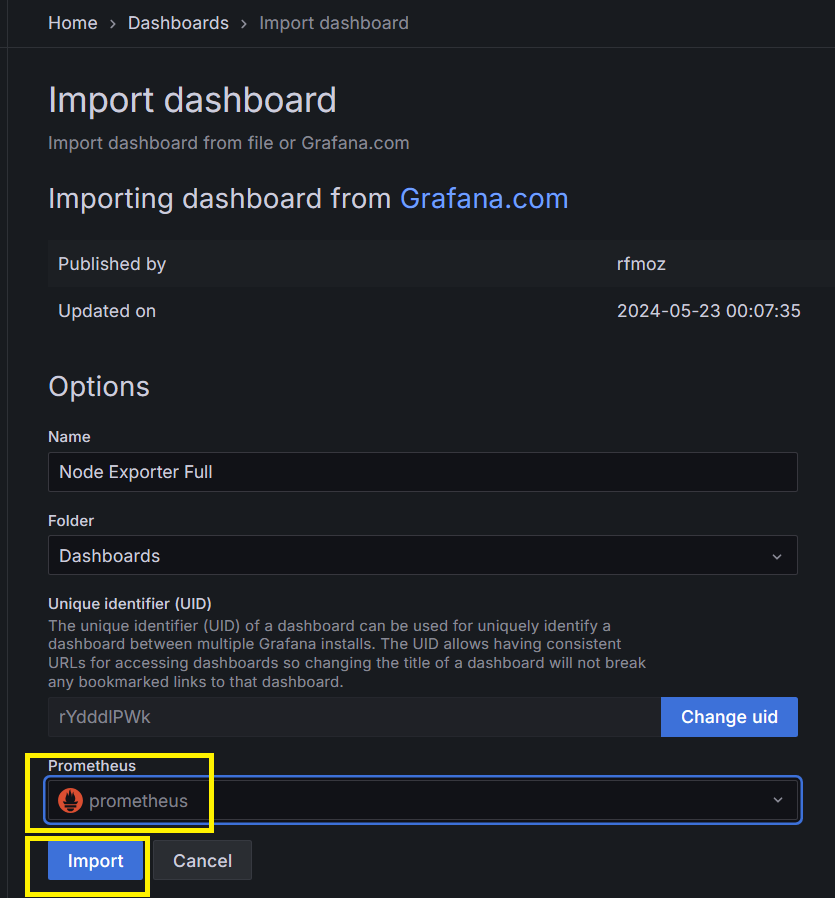
Step 16:Grafana儀錶板 - 配置 Node Exporter - 匯入完成
選擇 Prometheus -> Import
Step 17:Grafana儀錶板 - DEMO成果
可以在 DashBoard 上看到 CPU , Memory 等資訊,可以在右上角選擇 5s 加快刷新頻率
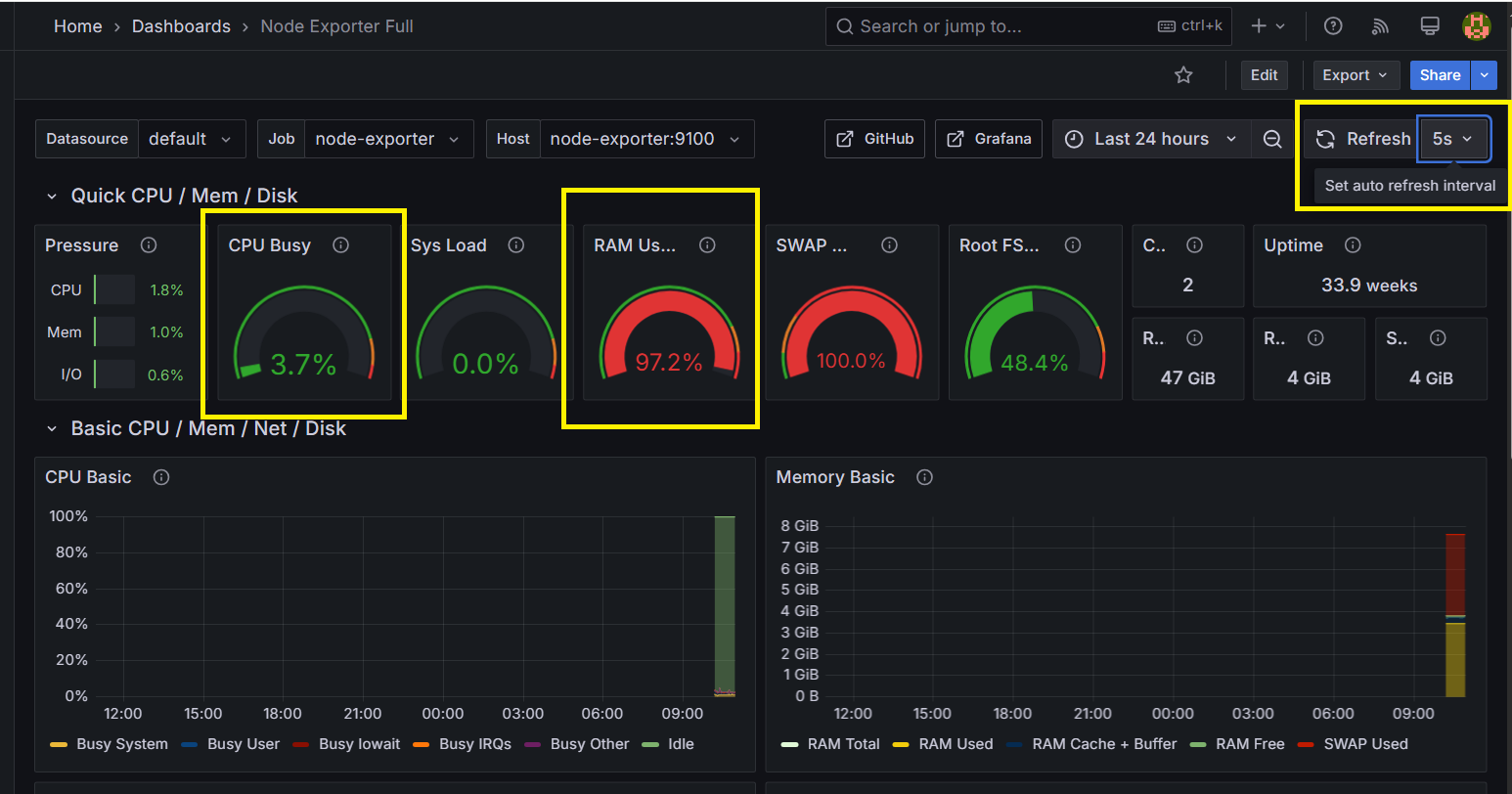
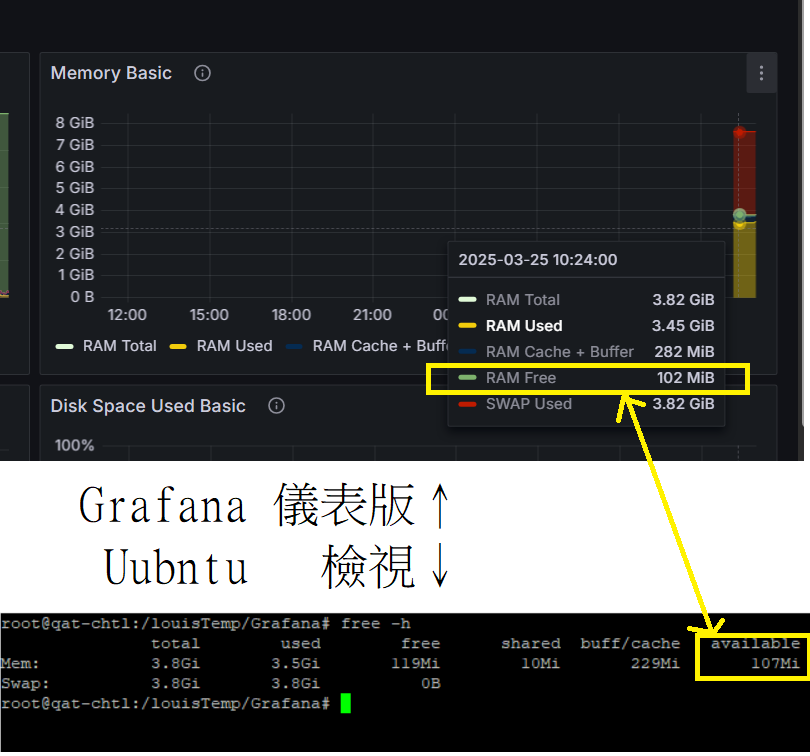
Step 18:Grafana儀錶板 - DEMO成果 - 證明一致
可在 Ubuntu 輸入,取得記憶體:
free -h
比對 Grafana 儀表板後確實記憶體已耗盡,完成 Grafana 監控硬體資源的實現。