日期:2024年 11月 16日
標籤: Redis Transaction Lua StackExchangeRedis
摘要:效能議題
應用所需:1. 已架設好 Redis 主機(本篇範例 7.4.0)
2. Visual Studio 2022 Asp.net Core
範例檔案:本篇範例代碼
相關參考:Redis For Windows 下載頁面
探討問題:Redis 資料插入效能比較:30,000 筆資料多種方法分析 — 比較交易模式、管道批次、壓縮與序列化、Lua 腳本插入方法的效能表現
基本介紹:本篇分為三大部分。
第一部分:定義目標與範圍
第二部分:執行測試
第三部分:分析結果 & 結論
第一部分:定義目標與範圍
Step 1:目標
找出最適合大量資料寫入的 Redis 方法,了解不同方法在不同情境下的表現差異。
Redis 官網文件中有提到幾中與 Redis 交互資料的方式。
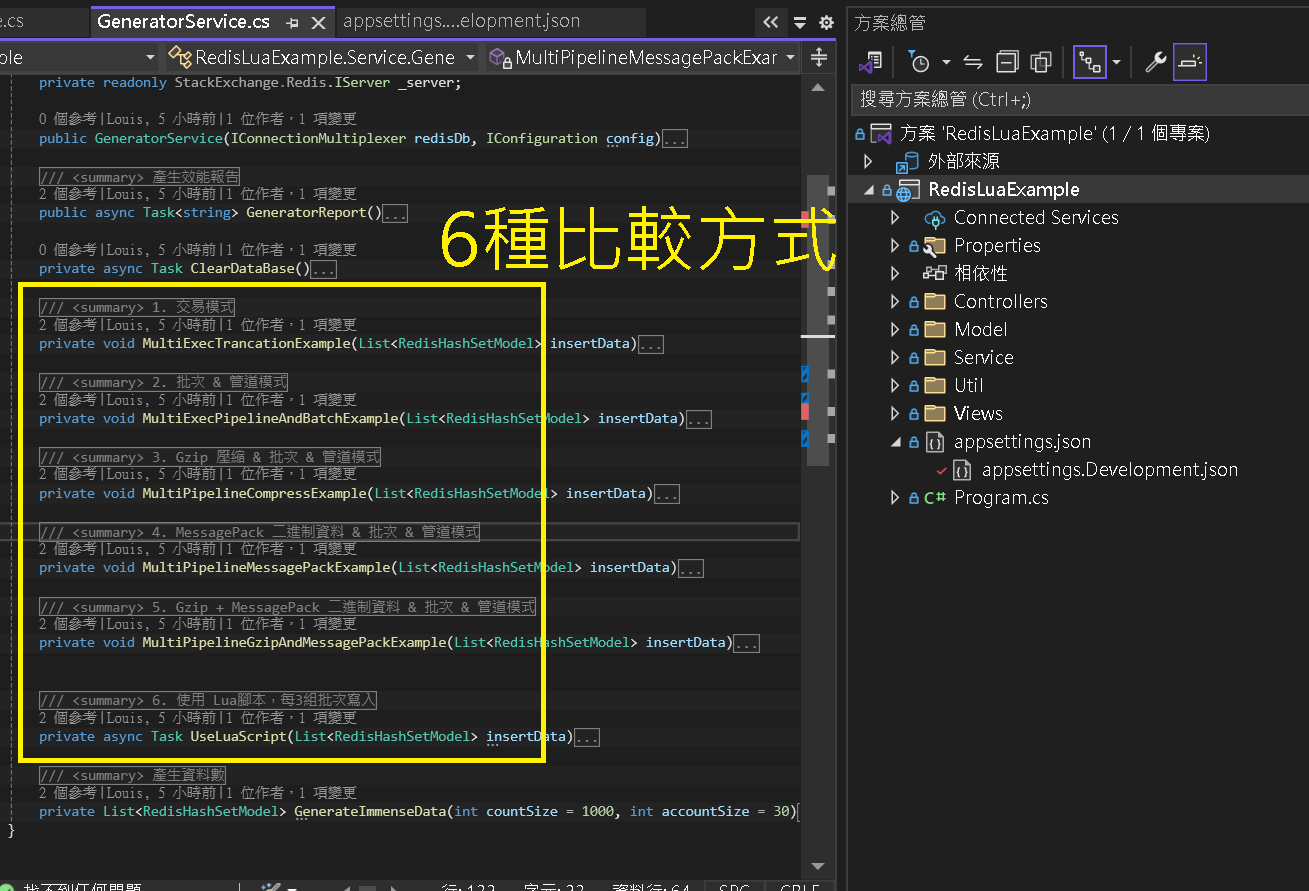
Step 2:測試專案與項目
範例代碼有以下專案架構,會有 6 種測試方式
| 1. 交易模式 | : | 使用 Redis 事務來執行多個命令,確保操作的原子性。 |
| 2. 管道批次 | : | 利用管道(Pipeline)技術批量發送命令,減少網路往返延遲。捨棄原子性。 |
| 3. Gzip 壓縮 & 批次 & 管道模式 | : | 在管道批次基礎上增加數據壓縮,減少傳輸數據量。 |
| 4. MessagePack 二進制資料 & 批次 & 管道模式 | : | 使用 MessagePack 將資料序列化為二進制格式,提升序列化/反序列化效率。 |
| 5. Gzip + MessagePack 二進制資料 & 批次 & 管道模式 | : | 結合 Gzip 壓縮和 MessagePack 序列化,進一步優化數據傳輸。 |
| 6. 使用 Lua 腳本,每3000筆為一組寫入 | : | 使用 Lua 腳本將多個操作封裝在一個原子操作中,減少網路往返次數。3 組批次共 3000 筆資料。 |
Step 3:執行測試與數據收集
基本測試方針:
| 1. 多次測試 | : | 對每種方法執行至少 5 次測試,取平均值以減少偶然誤差。 |
| 2. 記錄時間 | : | 除了總耗費時間外,還可以記錄每個操作的平均耗時和最大耗時。 |
| 3. 硬體設備 | : | 使用 Docker Container Redis 運行,所有測試都使用相同配備。 |
| 4. 相同資料量 | : | 每種方法都採用 30000 筆資料、相同 RedisKey、HashKey、 32 KB Json資料,每種方法批次寫入,都 1G 左右的資料量。 |
每次執行結果都會顯示於 Demo 頁面 (※其中 1 次結果畫面)

第二部分:執行測試
Step 1:取得共用數據 - 32 Kb Json
先透過隨機產生 Json 網站,製作 32 KB Json 資料
並且作為資料來源
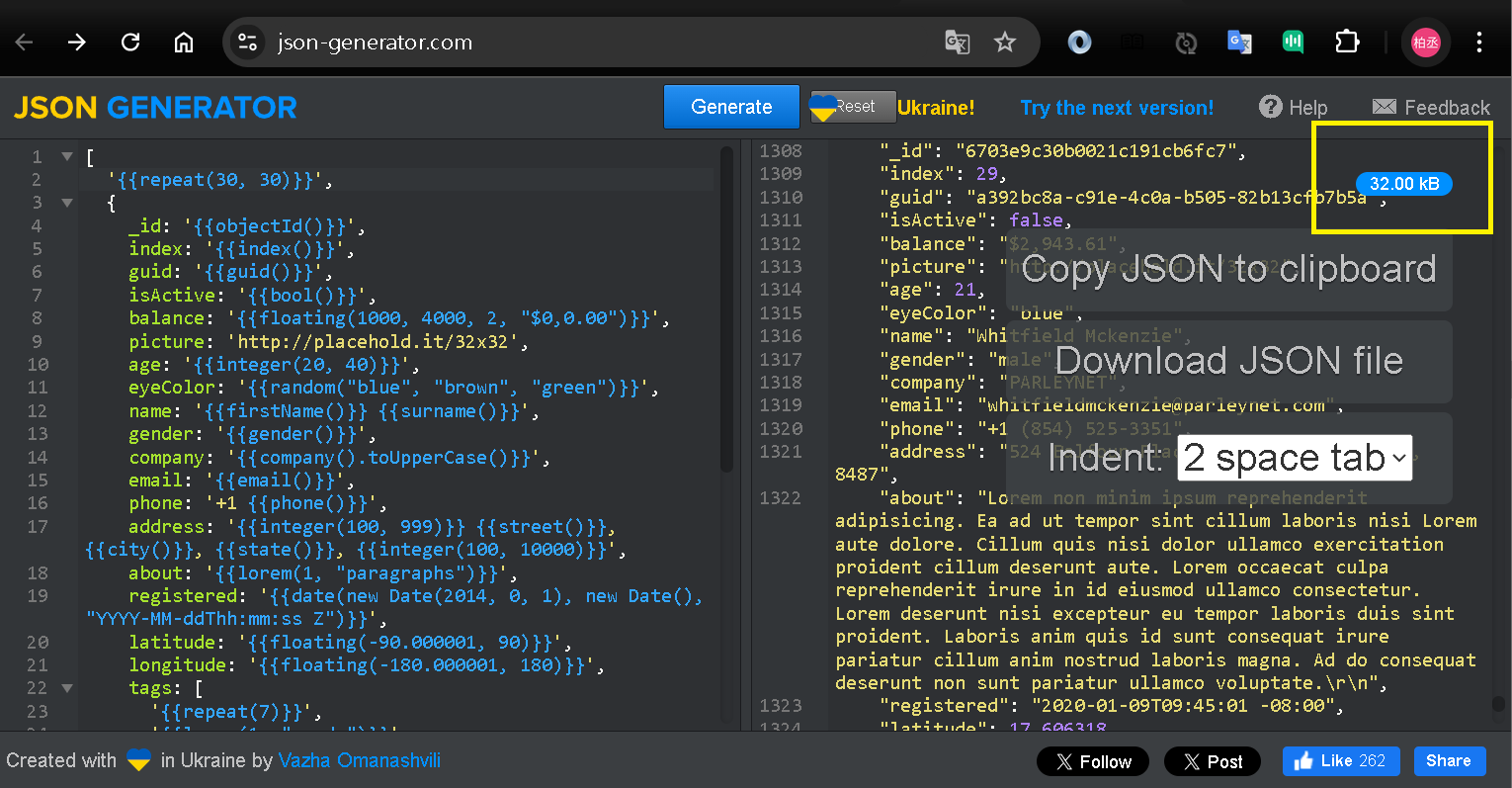
Step 2:產生共用數據 - 代碼
每個方法都是共用相同的資料,產生 30 組 RedisKey,1000 筆 HashSet 的 32 KB 資料。
每次寫入共 975 MB 接近 1G 的批次寫入。
/// <summary>
/// 產生資料數
/// </summary>
private List<RedisHashSetModel> GenerateImmenseData(int countSize = 1000, int accountSize = 30)
{
var testCollection = new List<RedisHashSetModel>();
var accountIds = GetAccountIds(accountSize: accountSize);
for (int index = 0; index < countSize; index++)
{
foreach (var accountId in accountIds)
{
var hashSetKey = index;
var redisKey = $@"Account:{accountId}";
testCollection.Add(new RedisHashSetModel()
{
HashKey = $@"{index}",
RedisKey = redisKey,
Data = CommonUtil.GetTestJSon
});
}
}
// 人數
List<int> GetAccountIds(int accountSize)
{
var result = new List<int>();
for (int accountId = 0; accountId < accountSize; accountId++)
{
result.Add(accountId);
}
return result;
}
return testCollection;
}
Step 3:執行測試 - 交易模式
切出每 100 筆資料開啟 Redis 的交易模式,這種模式保持了原子性,但一次量大時會占用大量 Redis 記憶體空間。
private void MultiExecTrancationExample(List<RedisHashSetModel> insertData)
{
var batchSize = 100;
for (int i = 0; i < insertData.Count(); i += batchSize)
{
var transaction = _db.CreateTransaction();
var batch = insertData.Skip(i).Take(batchSize);
foreach (var item in batch)
{
transaction.HashSetAsync(item.RedisKey, item.HashKey, item.Data);
}
// 提交事務
bool committed = transaction.Execute();
}
}
5 次執行結果如下
| 1. | 耗費:12.7598317 秒 |
| 2. | 耗費:13.2819952 秒 |
| 3. | 耗費:18.2613657 秒 |
| 4. | 耗費:15.2953010 秒 |
| 5. | 耗費:12.9500915 秒 |
Step 4:執行測試 - 批次 & 管道模式
使用 Redis Pipe 技術批量發送命令,減少網路往返延遲。捨棄原子性。
開啟 30000 個 Task 等待每個都完成。
private void MultiExecPipelineAndBatchExample(List<RedisHashSetModel> insertData)
{
var batch = _db.CreateBatch();
List<Task> tasks = new List<Task>();
foreach (var item in insertData)
{
tasks.Add(batch.HashSetAsync(item.RedisKey, item.HashKey, item.Data));
}
batch.Execute();
Task.WhenAll(tasks).Wait();
}
5 次執行結果如下
| 1. | 耗費:11.5598482 秒 |
| 2. | 耗費:11.2479852 秒 |
| 3. | 耗費:15.9268615 秒 |
| 4. | 耗費:14.1274140 秒 |
| 5. | 耗費:12.9500915 秒 |
Step 5:執行測試 - Gzip 壓縮 & 批次 & 管道模式
增加 Redis Value 支援的 Gzip,進行資料壓縮,嘗試效果。
private void MultiPipelineCompressExample(List<RedisHashSetModel> insertData)
{
var batch = _db.CreateBatch();
List<Task> tasks = new List<Task>();
foreach (var item in insertData)
{
byte[] gzipCompressed = CommonUtil.Compress(item.Data);
tasks.Add(batch.HashSetAsync(item.RedisKey, item.HashKey, gzipCompressed));
}
batch.Execute();
Task.WhenAll(tasks).Wait();
}
5 次執行結果如下
| 1. | 耗費:21.6775648 秒 |
| 2. | 耗費:21.3405034 秒 |
| 3. | 耗費:29.5351501 秒 |
| 4. | 耗費:26.0825542 秒 |
| 5. | 耗費:22.3025694 秒 |
用 Gzip 壓縮可到 10 Kb左右,壓縮率 66%
Step 6:執行測試 - MessagePack 二進制資料 & 批次 & 管道模式
使用 MessagePack 將資料序列化為二進制格式,提升序列化/反序列化效率,嘗試效果。
private void MultiPipelineMessagePackExample(List<RedisHashSetModel> insertData)
{
var batch = _db.CreateBatch();
var tasks = new List<Task>();
foreach (var item in insertData)
{
byte[] gzipCompressed = MessagePackSerializer.Serialize(item.Data);
tasks.Add(batch.HashSetAsync(item.RedisKey, item.HashKey, gzipCompressed));
}
batch.Execute();
Task.WhenAll(tasks).Wait();
}
5 次執行結果如下
| 1. | 耗費:12.2951671 秒 |
| 2. | 耗費:11.3835120 秒 |
| 3. | 耗費:16.2605253 秒 |
| 4. | 耗費:14.6539413 秒 |
| 5. | 耗費:12.4102970 秒 |
Step 7:執行測試 - Gzip + MessagePack 二進制資料 & 批次 & 管道模式
結合 Gzip 壓縮和 MessagePack 序列化,進一步優化數據傳輸。
private void MultiPipelineGzipAndMessagePackExample(List<RedisHashSetModel> insertData)
{
var batch = _db.CreateBatch();
var tasks = new List<Task>();
foreach (var item in insertData)
{
byte[] gzipCompressed = MessagePackSerializer.Serialize(item.Data);
tasks.Add(batch.HashSetAsync(item.RedisKey, item.HashKey, Compress(gzipCompressed)));
}
batch.Execute();
Task.WhenAll(tasks).Wait();
byte[] Compress(byte[] data)
{
using (var mso = new MemoryStream())
{
using (var gzip = new GZipStream(mso, CompressionLevel.Optimal))
{
gzip.Write(data, 0, data.Length);
}
return mso.ToArray();
}
}
}
5 次執行結果如下
| 1. | 耗費:22.7583919 秒 |
| 2. | 耗費:21.2645812 秒 |
| 3. | 耗費:28.9371520 秒 |
| 4. | 耗費:26.1719346 秒 |
| 5. | 耗費:22.9224340 秒 |
Step 8:執行測試 - 使用 Lua 腳本,每 3000 筆為一組寫入
使用 Lua 腳本將多個操作封裝在一個原子操作中,減少網路往返次數。
※Lua 預設最大值為 8000
private async Task UseLuaScript(List<RedisHashSetModel> insertData)
{
var accountGroups = insertData.GroupBy(x => x.RedisKey);
int totalHashes = insertData.Count();
int luaSize = 3000;//Server 如果沒有限制預設值是 8000
var keys = new List<RedisKey>();
var argv = new List<RedisValue>();
int count = 0;
foreach (var item in accountGroups)
{
keys.Add(item.Key);
foreach (var hashData in item)
{
argv.Add(hashData.HashKey);
argv.Add(hashData.Data);
count++;
// 當達到批次大小或最後一個 hash key,執行 Lua 腳本
if ((count + 1) % luaSize == 0 || count == totalHashes - 1)
{
var currentKeys = keys.ToArray();
var currentArgv = argv.ToArray();
var result = await _db.ScriptEvaluateAsync(GetluaScript(), currentKeys, currentArgv);
argv.Clear();
}
}
// 當達到批次大小或最後一個 hash key,執行 Lua 腳本
if ((count + 1) % luaSize == 0 || count == totalHs - 1)
{
var currentKeys = keys.ToArray();
var currentArgv = argv.ToArray();
var result = await _db.ScriptEvaluateAsync(GetluaScript(), currentKeys, currentArgv);
keys.Clear();
argv.Clear();
}
}
// Lua 腳本,簡單的 HashKey Value
string GetluaScript()
{
return @"
for i, key in ipairs(KEYS) do
local args = {}
for j = 1, #ARGV, 2 do
table.insert(args, ARGV[j]) -- 字段
table.insert(args, ARGV[j + 1]) -- 對應的值
end
-- 使用 HSET 一次設置多個字段
redis.call('HSET', key, unpack(args))
end
return 'OK'
";
}
}
5 次執行結果如下
| 1. | 耗費:20.9453106 秒 |
| 2. | 耗費:24.7206771 秒 |
| 3. | 耗費:23.5472192 秒 |
| 4. | 耗費:21.4723651 秒 |
| 5. | 耗費:23.6493003 秒 |
第三部分:分析結果 & 結論
Step 1:重複 5 次執行測試 - 總計
總耗時間與補充備註:
| 方法名稱 | 5次總耗時(秒) | 備註 |
|---|---|---|
| 交易模式 | 72.50 秒 | 使用事務,確保原子性 |
| 管道批次 | 65.78 秒 | 使用管道技術,減少網路往返 |
| Gzip 壓縮 & 批次 & 管道模式 | 120.92 秒 | 增加數據壓縮,減少傳輸量,壓縮時間列入計算 |
| MessagePack 二進制資料 & 批次 & 管道模式 | 66.99 秒 | 使用二進制序列化,效能較差 |
| Gzip + MessagePack 二進制資料 & 批次 & 管道模式 | 122.03 秒 | 結合壓縮與序列化,效能提升有限,壓縮時間列入計算 |
| 使用 Lua 腳本,每 3000 筆一組批次寫入 | 114.31 秒 | 使用 Lua 腳本 |
Step 2:重複 5 次執行測試 - 範圍區間
每種方法的平均、最大、最小耗時時間:
| 方法名稱 | 平均耗費時間(秒) | 最大耗費時間(秒) | 最小耗費時間(秒) |
|---|---|---|---|
| 交易模式 | 14.51 | 18.26 | 12.76 |
| 管道批次 | 13.16 | 15.92 | 11.25 |
| Gzip 壓縮 & 批次 & 管道模式 | 24.19 | 29.54 | 21.34 |
| MessagePack 二進制資料 & 批次 & 管道模式 | 13.40 | 16.26 | 11.38 |
| Gzip + MessagePack 二進制資料 & 批次 & 管道模式 | 24.41 | 28.94 | 21.26 |
| 使用 Lua 腳本,每 3000 筆一組批次寫入 | 22.87 | 24.72 | 20.95 |
Step 3:結論 & 適合場景與分析
交易模式
| 平均耗時: | 14.51 秒 |
| 分析: | 事務模式下,原子性確保了資料完整性,但平均和最大耗時都偏高,適合需要高度一致性的場景。 |
管道批次
| 耗時: | 13.16 秒 |
| 分析: | 管道批次顯著減少了網路往返,整體效能優於交易模式,適合對延遲敏感的場景,不需原子性的資料完整性。 |
Gzip 壓縮 & 批次 & 管道模式
| 耗時: | 24.19 秒 |
| 分析: | 壓縮雖然減少了傳輸數據量,但在小規模資料處理中壓縮反而造成了不必要的開銷,導致總體性能變差。 |
| 補充: | 實務上處裡資料傳送時,才會進行壓縮,因此將壓縮加入到插入 Redis 中。 |
| 若來源資料已壓縮的情況,會縮短至 8 秒左右(符合壓縮率 66%) |
MessagePack 二進制資料 & 批次 & 管道模式
| 耗時: | 13.40 秒 |
| 分析: | MessagePack 的二進制序列化帶來了良好的效能,但相比單純的管道批次,改善有限。 |
Gzip + MessagePack 二進制資料 & 批次 & 管道模式
| 耗時: | 24.41 秒 |
| 分析: | 結合壓縮和序列化的方式,預期中的效能提升並不明顯,兩者的處理開銷疊加,導致效能下降。 |
| 補充: | 實務上處裡資料傳送時,才會進行壓縮,因此將壓縮加入到插入 Redis 中。 |
| 若來源資料已壓縮的情況,會縮短至 8 秒左右(符合壓縮率 66%) |
使用 Lua 腳本,每 3000 筆一組批次寫入
| 耗時: | 22.87 秒 |
| 分析: | Lua 腳本批次寫入效能介於壓縮與管道模式之間,因為每批次執行 Lua 需額外的處理(組成文本、記憶體配置)時間。 |
| 具原子性,適合需要高度一致性的場景。 |