日期:2024年 08月 31日
標籤: Algorithm String Searching Algorithm C# Asp.NET Core
摘要:演算法-字串搜尋
m:找尋字串總長度 ; n:文本總長度 ;
時間複雜度(Time Complex):O(n)
空間複雜度: O(n)
範例檔案:Source Code
範例專案:Code Project
基本介紹:本篇分為3大部分。
第一部分:字典樹(前綴樹)演算法 - 介紹
第二部分:字典樹(前綴樹)演算法 - 實現
第三部分:字典樹(前綴樹)演算法 - 圖解
第一部分:字典樹(前綴樹)演算法 - 介紹
Step 1:簡介
以下截取於Wiki
在電腦科學中,trie,又稱字首樹或字典樹,是一種有序樹,用於儲存關聯陣列,其中的鍵通常是字串。
與二元搜尋樹不同,鍵不是直接儲存在節點中,而是由節點在樹中的位置決定。
一個節點的所有子孫都有相同的字首,也就是這個節點對應的字串,而根節點對應空字串。
一般情況下,不是所有的節點都有對應的值,只有葉子節點和部分內部節點所對應的鍵才有相關的值。
簡言之,搜尋一串字串(文本),用此演算法適合找相關聯前綴匹配的應用場景
※來源:Wiki

Step 2:優缺點
優點具有以下:
| 1. Hash插入 | : | 高效的前綴搜索和插入操作。 |
| 2. 查詢效率高 | : | 使用Hash建樹的關係,因此查詢上能夠處理大量單詞,適合需要快速搜索和頻繁插入新單詞的應用。 |
缺點:
| 1. 預處理開銷大 | : | 空間效率較低,特別是當文本很大時。 |
| 2. 不適用單項查詢 | : | 不適合處理單個長文本的模式匹配,因為構建字典樹的初始成本較高。 |
Step 3:預處理樹 - 說明
以下出自 Wiki :
一個儲存了8個鍵的trie結構,"A", "to", "tea", "ted", "ten", "i", "in", "inn".
要先將文本建構成樹,查詢時再遍歷此樹,因此可實現相匹配接近的字串

第二部分:字典樹(前綴樹)演算法 - 實現
Step 1:建構式 - 進入
在建構式中,會將傳入的字串做分割,以 ‘ ‘ 空白字元切出每個單詞。
其中 TrieNode 是一個類別節點
private readonly TrieNode root;
/// <summary>
/// 1. 建構子
/// </summary>
/// <param name="text"></param>
public TrieAlgorithm(string text)
{
root = new TrieNode();
var textSplite = text.Split(' ');
foreach (var item in textSplite)
{
this.Insert(item);
}
}
Step 2:建構式 - 樹結構
樹結構,每個節點都會產生字元對應字典表,如果有重複的前綴項目可重複利用。
/// <summary>
/// 樹結構
/// </summary>
public class TrieNode
{
/// <summary>
/// 字元與子節點的映射
/// </summary>
public Dictionary<char, TrieNode> Children { get; private set; }
/// <summary>
/// 是否為字的結尾
/// </summary>
public bool IsEndOfWord { get; set; }
/// <summary>
/// 建構子
/// </summary>
public TrieNode()
{
Children = new Dictionary<char, TrieNode>();
IsEndOfWord = false;
}
}
Step 3:建構式 - 建構過程
樹建構的過程中會將文本 Text 插入(Insert)到樹中
/// <summary>
/// 1-2. 插入文本到字典樹中
/// </summary>
/// <param name="text">文本</param>
public void Insert(string text)
{
// 1-3. 從根節點開始
TrieNode currentNode = root;
foreach (char c in text)
{
// 1-4. 若不存在,則新增節點
if (!currentNode.Children.ContainsKey(c))
{
currentNode.Children[c] = new TrieNode();
}
// 1-5. 移動到下一個節點
currentNode = currentNode.Children[c];
}
// 1-6. 標記為字的結尾
currentNode.IsEndOfWord = true;
}
Step 4:建構式 - 搜尋單詞
搜尋完整的單詞時,必須完全匹配,因此 2-2. 若字元沒有在當前樹節點中找到
則表示不存在,回傳 False
如果完全匹配,但是 IsEndOfWord = false ,表示是某個字串中的一部分,沒有完全匹配,也是回傳 False
EX: Text:”HERE” Pattern=”HER”
這時 HE”R” 的匹配時,樹 IsEndOfWord = false 所以表示沒有這個單詞。
/// <summary>
/// 2. 搜尋字典樹中是否包含某個字
/// </summary>
/// <param name="pattern">查找字串</param>
/// <returns></returns>
public bool Search(string pattern)
{
TrieNode currentNode = root;
// 2-1. 從根節點開始
foreach (char c in pattern)
{
if (!currentNode.Children.ContainsKey(c))
{
// 2-2. 若不存在,返回 false
return false;
}
// 2-3. 移動到下一個節點
currentNode = currentNode.Children[c];
}
return currentNode.IsEndOfWord;
}
Step 5:建構式 - 搜尋前綴
查詢前綴則是找到完全匹配 Pattern 時則視為找到,因此 Pattern 遍歷完成後,可回傳 True
/// <summary>
/// 3. 搜尋字典樹中是否包含某個前綴
/// </summary>
/// <param name="prefix">查找字串 (部分字串)</param>
/// <returns></returns>
public bool StartsWith(string prefix)
{
TrieNode currentNode = root;
// 3-1. 從根節點開始
foreach (char c in prefix)
{
if (!currentNode.Children.ContainsKey(c))
{
// 3-2. 若不存在,返回 false
return false;
}
// 3-3. 移動到下一個節點
currentNode = currentNode.Children[c];
}
// 3-4. 表示找到前綴
return true;
}
第三部分:字典樹(前綴樹)演算法 - 圖解
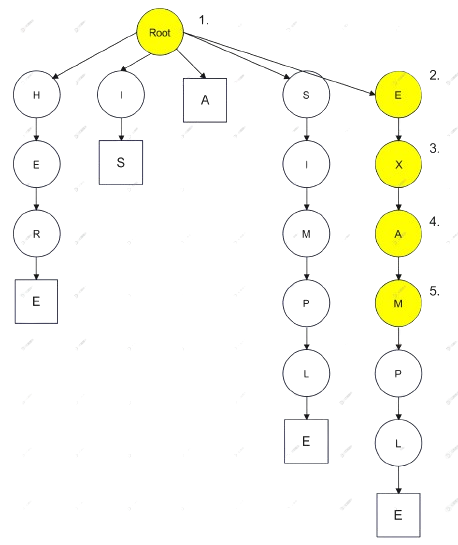
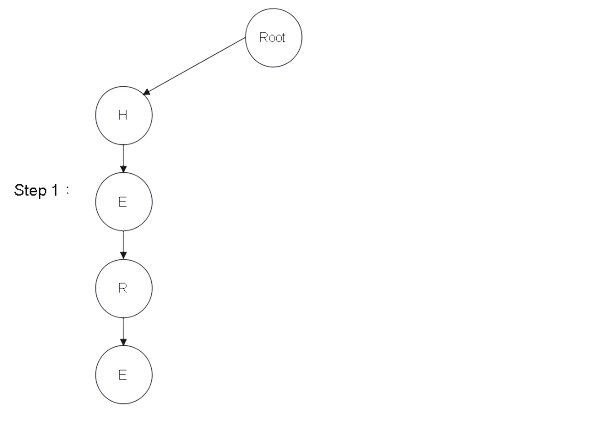
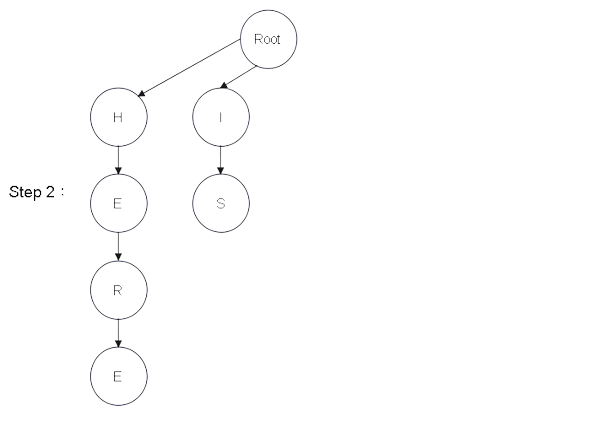
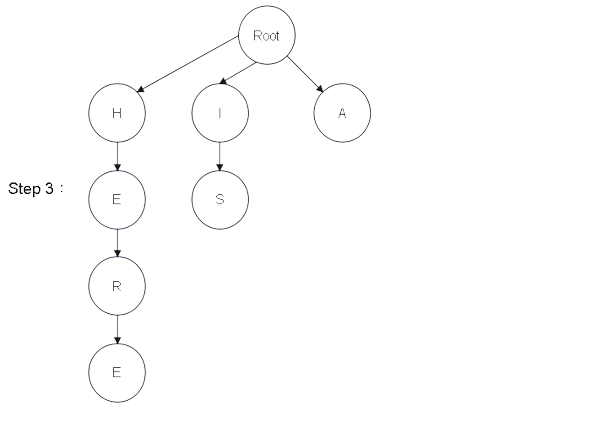
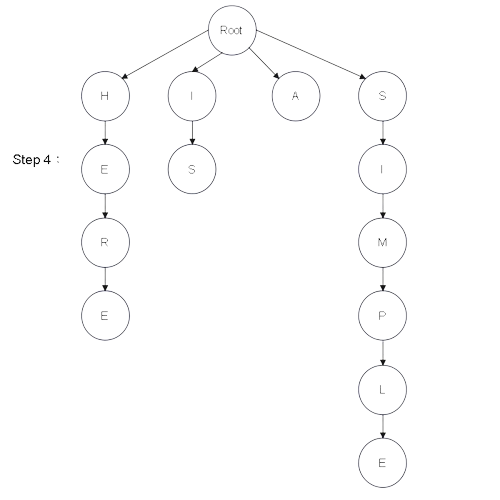
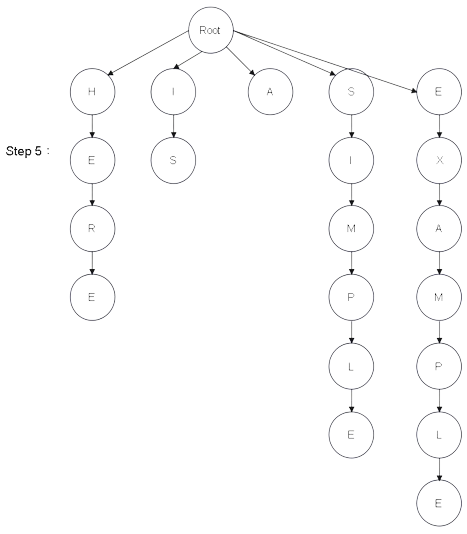
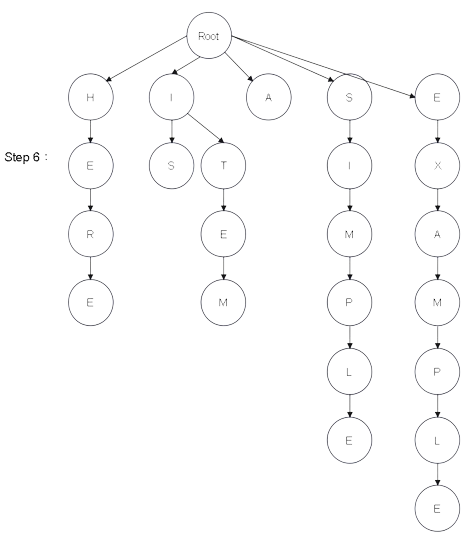
Step 1:建樹 - 圖解
從建構式進入,會產生一個 Root 根結點
| 文本 : HERE IS A SIMPLE EXAMPLE ITEM |
然後建構式會觸發 Insert() 將文本拆成以下 6 個單詞:
| HERE |
| IS |
| A |
| SIMPLE |
| EXAMPLE |
| ITEM |
並且依序建構成樹結構
Step 2:搜尋單詞
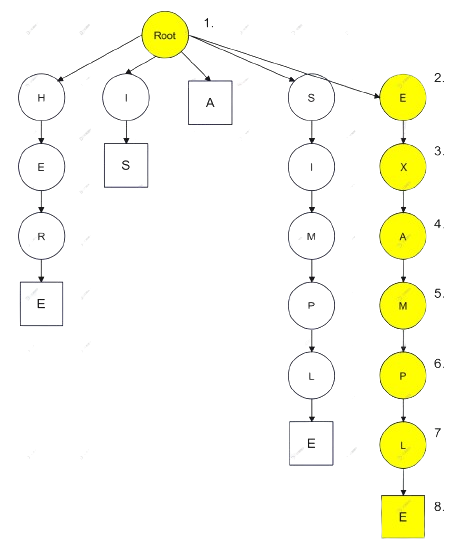
從 Search() 進入後,找出搜尋字串
| 文本 : HERE IS A SIMPLE EXAMPLE |
| 搜尋 : EXAMPLE |
持續匹配直到回傳樹葉節點(最終節點),而回傳是否找到,
EXAMPLE 都找到後,確認是否停留在樹葉節點上,若是就表示完全匹配。
※以正方形當作樹葉節點
Step 3:搜尋前綴
從 StartsWith() 進入後,找出搜尋字串
| 文本 : HERE IS A SIMPLE EXAMPLE |
| 搜尋 : EXAM |
持續匹配直到搜尋字串全部匹配完成,回傳找到,否則回傳沒有
EXAM 都找到後,無論是否停留在樹葉上,