日期:2024年 08月 03日
標籤: Algorithm String Searching Algorithm C# Asp.NET Core
摘要:演算法-字串搜尋
m:文本總長度 ; n:找尋字串總長度
時間複雜度(Time Complex):O(m + n)
最佳時間: O(m)
最壞時間: O(m + n)
空間複雜度: O(n)
範例檔案:Source Code
範例專案:Code Project
基本介紹:本篇分為3大部分。
第一部分:KMP演算法 - 介紹
第二部分:KMP演算法 - 代碼
第三部分:KMP演算法 - 圖解說明
第一部分:KMP演算法 - 介紹
Step 1:簡介
以下截取於Wiki
在電腦科學中,克努斯-莫里斯-普拉特字串尋找演算法(英語:Knuth–Morris–Pratt algorithm,簡稱為KMP演算法)可在一個字串S內尋找一個字W的出現位置。
一個詞在不匹配時本身就包含足夠的資訊來確定下一個匹配可能的開始位置,此演算法利用這一特性以避免重新檢查先前配對的字元。
這個演算法由高德納和沃恩·普拉特在1974年構思,同年詹姆斯·H·莫里斯也獨立地設計出該演算法,最終三人於1977年聯合發表。
簡言之,搜尋一串字串(文本),用此演算法最佳 & 最壞表現都維持在線性時間複雜度
※來源:Wiki

Step 2:優缺點
優點具有以下:
| 1. 高效率 | : | KMP演算法的時間複雜度最壞是 𝑂(𝑛+𝑚),最好可以到 𝑂(𝑚) 表示永遠都在線性時間內 |
| 2. 避免多餘的比較 | : | 建立匹配表後,可以跳過重複的比對,避免發生暴力搜尋法不必要的開銷 |
缺點:
| 1. 額外空間開銷 | : | 需要額外的 𝑂(𝑛) 的查找目標字串的空間,來產生匹配表,在記憶體稀缺的狀況下不建議使用 (嵌入式設備 EX:手錶) |
| 2. 複雜度高 | : | 與其他算法相比,此算法的實現複雜度較高,要有一定的理解才能明白匹配表跳過機制 |
| 3. 特殊字符額外開銷 | : | 因為額外的 𝑂(𝑛) 匹配表,若是有中文保存的將會是 UTF-8 / UTF-16 / UTF-32 (至少額外 4 Bytes)… |
Step 3:預處理匹配表(失配函數) - 說明
KMP 核心是透過預先使用失配函數,產生查找字串的匹配表,讓搜尋的過程中,不用每次都從頭開始查詢。
以下出自 Wiki :
部分匹配表,又稱為失配函式,作用是讓演算法無需多次匹配S中的任何字元。
能夠實現線性時間搜尋的關鍵是在主串的一些欄位中檢查模式串的初始欄位,可以確切地知道在當前位置之前的一個潛在匹配的位置。
換句話說,在不錯過任何潛在匹配的情況下,"預搜尋"這個模式串本身並將其譯成一個包含所有可能失配的位置對應可以繞過最多無效字元的列表。
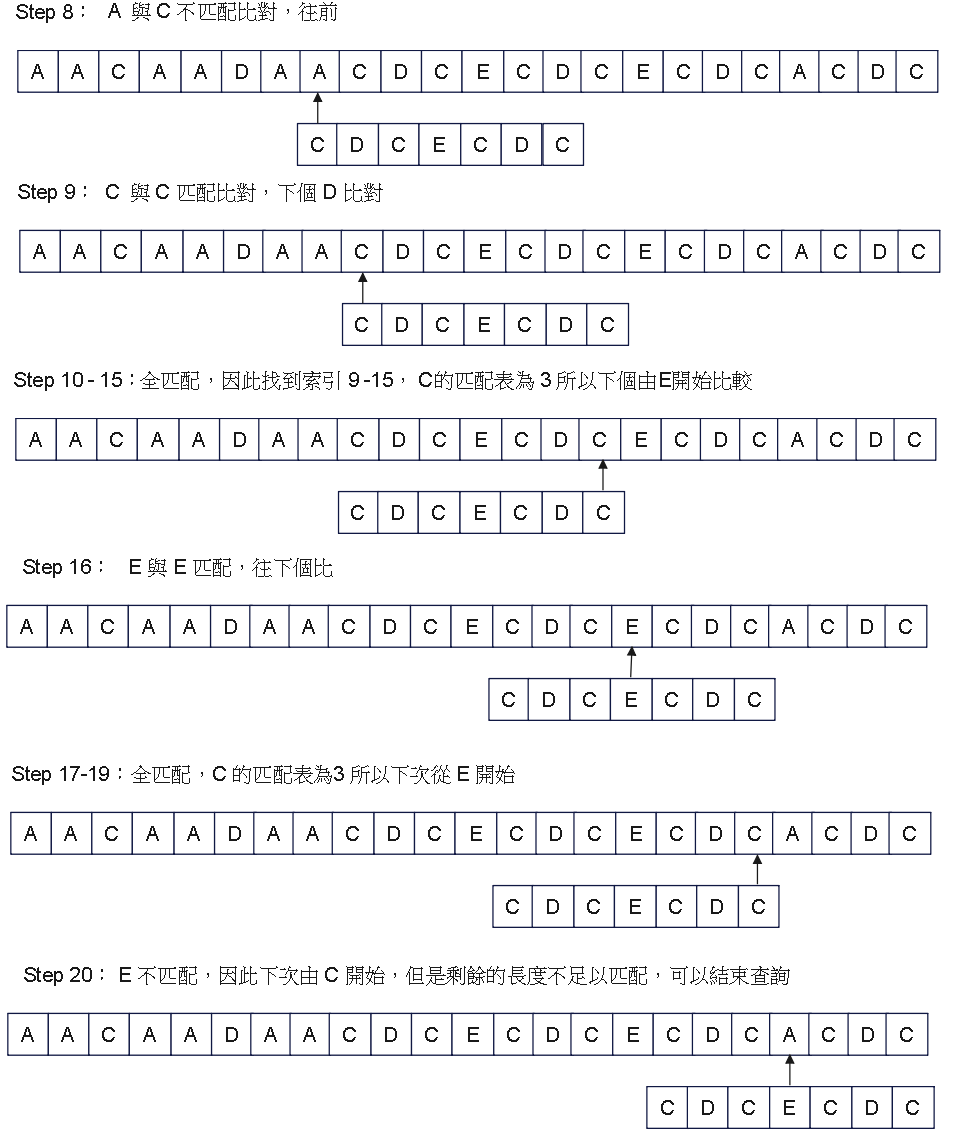
Step 4:預處理匹配表(失配函數) - 圖解1
假設想要 Google 搜尋 “CDCECDC” ,會產生以下,其中產生過程為 O(n)
\[\begin{array}{|c|c|c|c|c|c|c|} \hline C & D & C & E & C & D & C \\ \hline 0 & 0 & 1 & 0 & 1 & 2 & 3 \\ \hline \end{array}\]
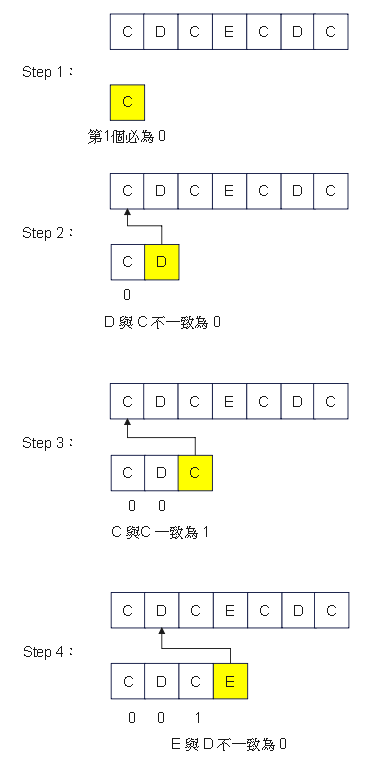
Step 4:預處理匹配表(失配函數) - 圖解2
最終取得 [0, 0, 1, 0, 1, 2, 3] 匹配表
第二部分:KMP演算法 - 代碼
Step 1:建構式 - 進入
以下為範例代碼的進入點,有兩種文本,便於說明。
public class KMPAlgorithmExecute
{
/// <summary>
/// KMP 字串搜尋演算法 - 進入點
/// </summary>
public void Execute()
{
var method = new KMPAlgorithm();
string target1 = "CECDCEDCCDCECDCCDC";
string target2 = "AACAADAACDCECDCECDCACDC";
string pattern = "CDCECDC";
List<int> matchPositions = method.KMPSearch(target1, pattern);
Console.WriteLine($"文本:{target1} 匹配位置:");
foreach (int pos in matchPositions)
{
Console.WriteLine(pos);
}
Console.WriteLine("");
Console.WriteLine($"文本:{target2} 匹配位置:");
matchPositions = method.KMPSearch(target2, pattern);
foreach (int pos in matchPositions)
{
Console.WriteLine(pos);
}
}
}
Step 2:主程式 - KMP查找字串
主程式包含了 3 部分,其中第 2 部分 ComputePrefixFunction(patternStr); 會找出匹配表。
/// <summary>
/// KMP - 字串搜尋
/// </summary>
public List<int> KMPSearch(string targetStr, string patternStr)
{
// 1. 建構變數
int tragetLength = targetStr.Length;
int patternLength = patternStr.Length;
// 2. 計算部分匹配表 (正式名稱:失配函式)
var matchTable = ComputePrefixFunction(patternStr);
int currentIndex = 0;// 當前匹配的位置
var resultMatch = new List<int>();
// 3. PMT 用 Match表找出文本(targetStr) 的比對資料
for (int index = 0; index < tragetLength; index++)
{
// 3-1. 比對字串這次是否有匹配,若沒有匹配,則將 Match表內公共前綴索引倒退為前一次查找相同字符結果
while (currentIndex > 0 &&
targetStr[index] != patternStr[currentIndex])
{
currentIndex = matchTable[currentIndex - 1];
}
// 3-2. 比對字串字符相同,繼續往前比對
if (targetStr[index] == patternStr[currentIndex])
{
currentIndex++;
}
// 3-3. 若當前查找全部匹配,則記錄匹配位置
if (currentIndex == patternLength)
{
// 此段為記錄索引,因此相減後+1
resultMatch.Add(index - patternLength + 1);
// 因為比對完成,強制將查找索引,往 Match 表前一個最常公共前綴查找
currentIndex = matchTable[currentIndex - 1];
}
}
return resultMatch;
}
Step 3:子函數 - 失配函式找出匹配表
在預處理時會執行失配函式,並且產生出匹配表
/// <summary>
/// 2. 計算部分匹配表 (正式名稱:失配函式)
/// </summary>
public int[] ComputePrefixFunction(string pattern)
{
var matchTable = new int[pattern.Length];
int commonIndex = 0;// 最常公共前綴後綴長度
// 2-1. 跳過自己跟自己比對,因此從第二個字符 (serachIndex = 1) 開始計算
for (int serachIndex = 1; serachIndex < pattern.Length; serachIndex++)
{
// 2-2. 檢查這次是否有匹配,若沒有匹配,則將 commonIndex 當前公共前綴索引倒退為前一次查找相同字符結果
// (若都無最後 commonIndex 會為 0)
while (commonIndex > 0 &&
pattern[serachIndex] != pattern[commonIndex])
{
commonIndex = matchTable[commonIndex - 1];
}
// 2-3. 本次若匹配到,累計最常公共前綴
if (pattern[serachIndex] == pattern[commonIndex])
{
commonIndex++;
}
// 2-4. 每次都將匹配結果紀錄
matchTable[serachIndex] = commonIndex;
}
return matchTable;
}
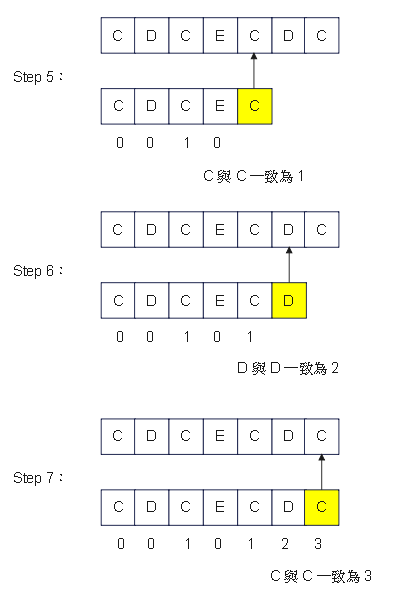
第三部分:KMP演算法 - 圖解說明
Step 1:圖解 - 1
使用文本 : AACAADAACDCECDCECDCACDC
搜尋字串 : CDCECDC
搜尋字串匹配表 [0, 0, 1, 0, 1, 2, 3]
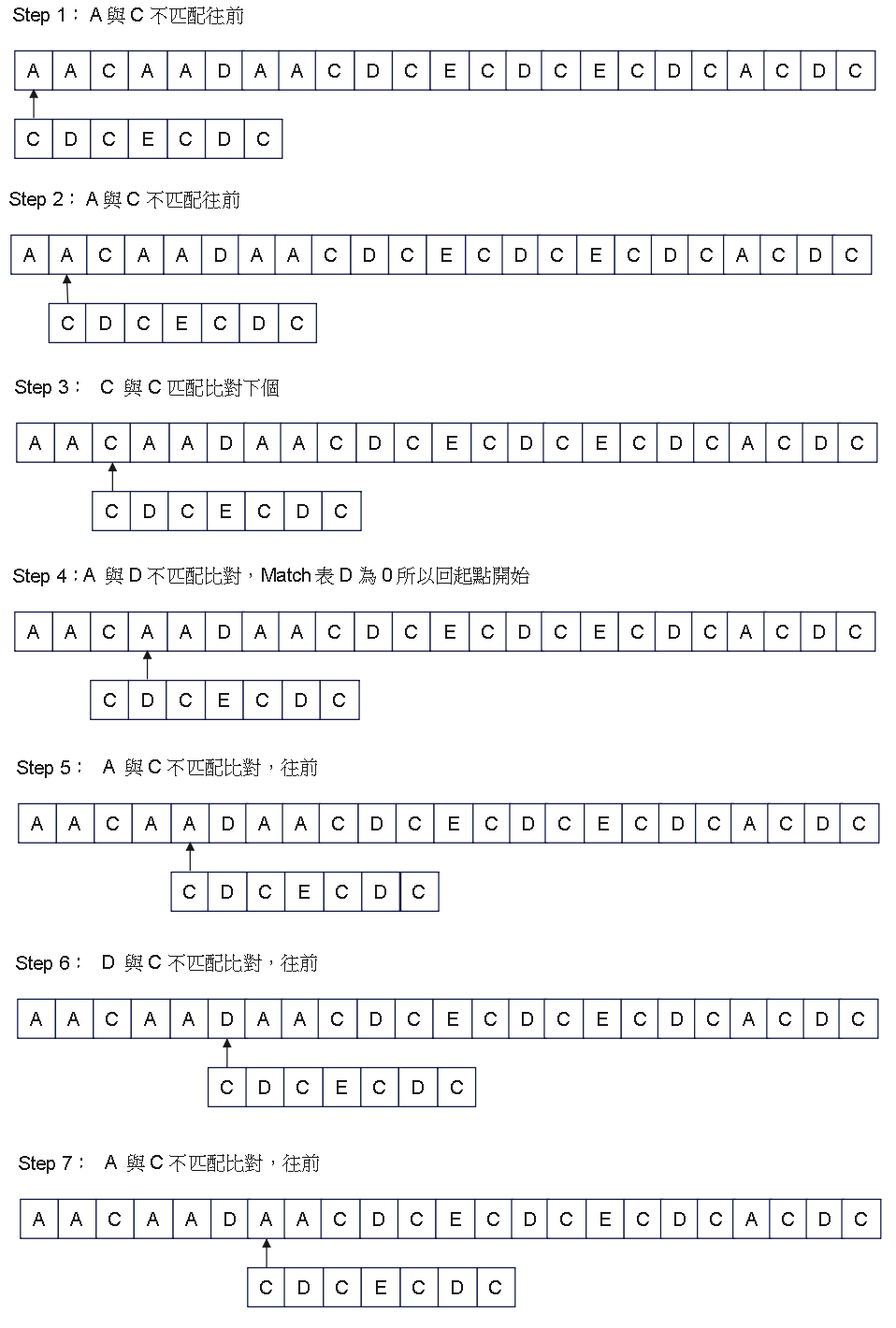
Step 2:圖解 - 2
使用文本 : AACAADAACDCECDCECDCACDC
搜尋字串 : CDCECDC
搜尋字串匹配表 [0, 0, 1, 0, 1, 2, 3]
最後可以發現當查詢字串重複愈多的情況下,效果越好,並且始終查詢過程在線性時間,相當高效