日期:2024年 06月 30日
標籤: Algorithm String Searching Algorithm C# Asp.NET Core
摘要:演算法-字串搜尋
m:文本總長度 ; n:找尋字串總長度
時間複雜度(Time Complex):O(m + n)
最佳時間: O(m + n)
最壞時間: O(mn)
範例檔案:Source Code
範例專案:Code Project
基本介紹:本篇分為5大部分。
第一部分:拉賓卡普演算法 - 介紹
第二部分:旋轉哈希 - 代碼
第三部分:旋轉哈希 - 圖解說明
第四部分:拉賓指紋 - 代碼
第五部分:拉賓指紋 - 圖解說明
第一部分:拉賓卡普演算法 - 介紹
Step 1:簡介
以下截取於Wiki
是一種由理察·卡普與麥可·拉賓於1987年提出的、使用雜湊函式以在文字中搜尋單個模式串的字串搜尋演算法單次匹配。
該演算法先使用旋轉雜湊以快速篩出無法與給定串匹配的文字位置,此後對剩餘位置能否成功匹配進行檢驗。
此演算法可推廣到用於在文字搜尋單個模式串的所有匹配或在文字中搜尋多個模式串的匹配。
簡言之,搜尋一串字串(文本),用此演算法最佳表現維持在線性時間複雜度
※來源:Wiki

Step 2:優缺點
優點具有以下:
| 1. 高效率 | : | 在平均情況下,拉賓-卡普演算法的時間複雜度是 𝑂(𝑛+𝑚),處理大量字串匹配問題時非常高效。 |
| 2. 處理多模式匹配 | : | 適合處理多模式匹配問題,例如網頁搜尋功能,查找自己網站內符合用戶搜尋的關鍵字 |
| 3. 簡單易用 | : | 實現相對簡單,如果可限定語言的情況下。 |
| 4. 雜湊函數靈活性 | : | 可動態使用不同的雜湊函數來適應不同的需求。 |
缺點:
| 1. 雜湊衝突 | : | 性能高度依賴於雜湊函數的質量。儘管好的雜湊函數可以減少衝突,但在最壞情況下(大量雜湊衝突),時間複雜度可能會退化到 O(m * n) |
| 2. 滾動雜湊複雜 | : | 雖然雜湊函數具靈活性,但自定義新的雜湊函式,需設計正確的雜湊滾動方式。 |
| 3. 依賴質數、基數選擇 | : | 需要選擇合適的基數和質數來平衡雜湊計算和衝突減少 |
Step 3:本篇2種算法 - 旋轉哈希 & 拉賓指紋
拉賓卡普演算法 + 旋轉哈希 適合用於快速理解這個演算法的本質
拉賓卡普演算法 + 拉賓指紋,則是大幅度的讓這個演算法的時間複雜度在通常情況下接近線性時間。
※碰撞愈少愈能達到 O(m + n) ; 反之碰撞愈多則會到 O(m * n)
| 特性 | 旋轉哈希 | 拉賓指紋 |
|---|---|---|
| 1. 碰撞率 | 高 | 低 |
| 2. 實現複雜度 | 低 | 高 |
| 3. 適用範圍 | 環形數組或字符串 | 各種字符串匹配問題 |
| 4. 計算效率 | 更新簡單,但碰撞率高 | 滾動哈希效率高,計算複雜 |
| 5. 依賴質數選擇 | 不依賴 | 依賴 |
第二部分:旋轉哈希 - 代碼
Step 1:建構式 - 進入
/// <summary>
/// 建構式
/// </summary>
/// <param name="text">原始資料</param>
/// <param name="pattern">查詢的字串</param>
public Method_RollingHash(string text, string pattern)
{
int result = RabinKarpSearch(text, pattern);
if (result != -1)
{
Console.WriteLine($"Pattern found at index {result}");
}
else
{
Console.WriteLine("Pattern not found");
}
}
Step 2:主程式
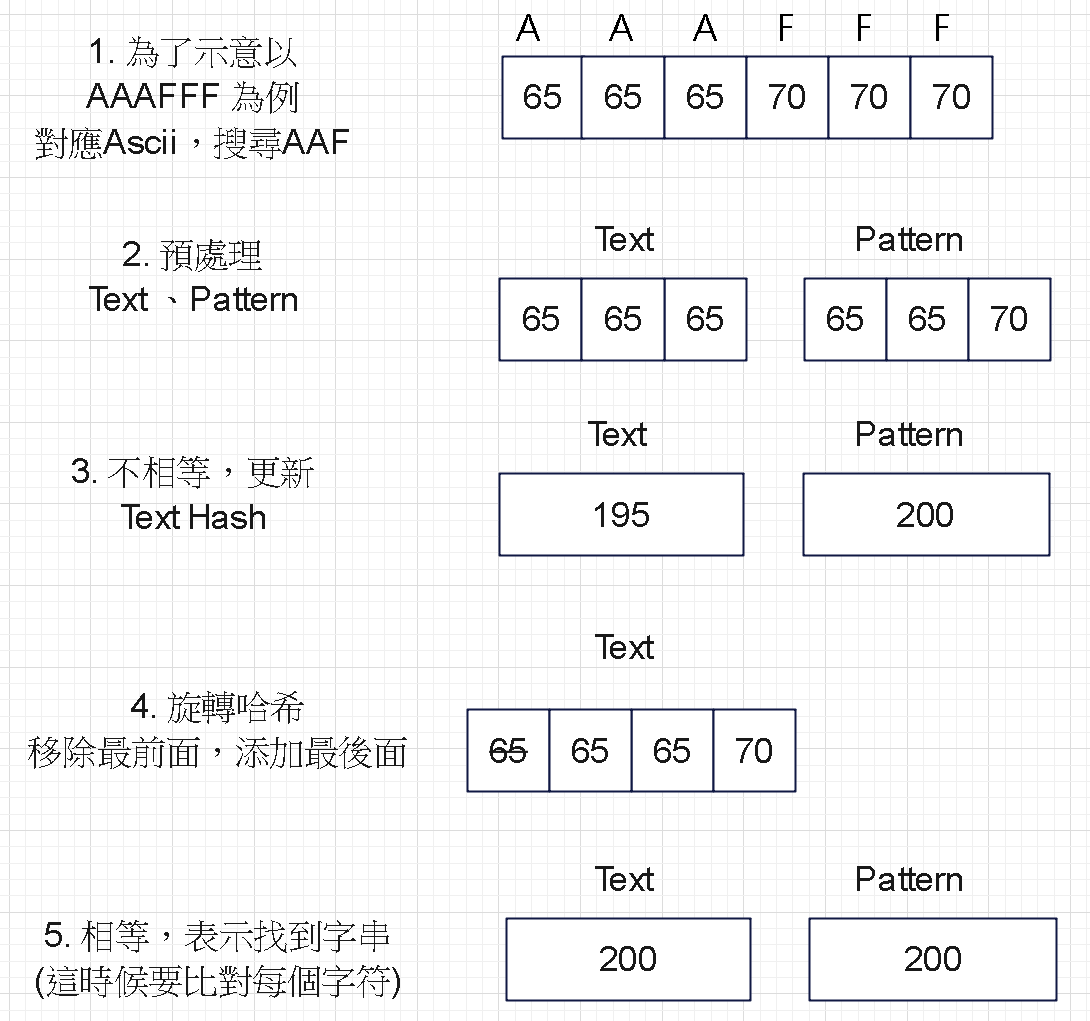
主程式包含了 5 大部分,每次沒有比對到後用 旋轉哈希 (Rolling Hashes) 產生下一個哈希值,繼續比對。
/// <summary>
/// 拉賓卡普搜索算法 - 旋轉哈希 (Rabin-Karp Algorithm)
/// </summary>
/// <param name="text">原始資料</param>
/// <param name="pattern">查詢的字串</param>
/// <returns></returns>
private int RabinKarpSearch(string text, string pattern)
{
// 1. 預處理:計算文字和查詢對象的 Hash
int textLength = text.Length;
int targetLength = pattern.Length;
int patternHash = CalculateRollingHash(pattern, 0, targetLength);
int textHash = CalculateRollingHash(text, 0, targetLength);
// 2. 滑動窗口處理 ※最多滑動 textLength - targetLength 次
for (int index = 0; index <= textLength - targetLength; index++)
{
// 3-1. 匹配,如果 Hash 相等,則進一步比較
if (patternHash == textHash)
{
int findIndex = 0;
// 3-2. 進一步比較,比對字元是否相等
// ※旋轉哈希有可能碰撞,所以需要進一步比對 EX: ABCD 與 DCBA 相同 Hash
for (; findIndex < targetLength; findIndex++)
{
if (text[index + findIndex] != pattern[findIndex])
break;
}
// 4. 如果完全匹配,返回索引
if (findIndex == targetLength)
return index;
}
// 3-3. 不匹配,更新 Hash 值
if (index < textLength - targetLength)
{
textHash = UpdateRollingHash(textHash, text[index], text[index + targetLength]);
}
}
// 5. 沒找到,返回 -1
return -1;
}
Step 3:子函數 - 取得文本某個區塊的哈希值
在預處理時會將搜尋目標、文本的前幾個字串(基於搜尋目標長度),產生初始哈希值。
/// <summary>
/// 計算 Hash 值 (累加字符的 ASCII 值)
/// </summary>
/// <param name="str">傳入的字串</param>
/// <param name="start">起始索引</param>
/// <param name="length">總長度</param>
/// <returns></returns>
private int CalculateRollingHash(string str, int start, int length)
{
int hash = 0;
for (int index = start; index < start + length; index++)
{
hash += str[index];
}
return hash;
}
Step 4:子函數 - 旋轉哈希
沒找到時,對下一個字符做哈希的產生
※旋轉哈希 - 用 Ascii 碼做加減法運算做 Hash 值,簡單,但註定會碰撞
※EX: ABC 與 CBA 都會碰撞到相同的 Ascii 加總值,每多一次碰撞,就會浪費一次搜尋機會。
/// <summary>
/// 沒找到時進入 - 更新旋轉 Hash 值
/// <para>※只有一個字元的變動</para>
/// </summary>
/// <param name="oldHash">當前舊有的 Hash 值</param>
/// <param name="oldChar">舊的單一字元</param>
/// <param name="newChar">新的單一字元</param>
/// <returns></returns>
private int UpdateRollingHash(int oldHash, char oldChar, char newChar)
{
return oldHash - oldChar + newChar;
}
第三部分:旋轉哈希 - 圖解說明
Step 1:圖解
第四部分:拉賓指紋 - 代碼
Step 1:建構式 - 進入
/// <summary>
/// 建構式
/// </summary>
/// <param name="text">原始資料</param>
/// <param name="pattern">查詢的字串</param>
public Method_RabinFingerprint(string text, string pattern)
{
// 使用質數 prime 進行模運算
int prime = 101;
int result = RabinKarpSearch(text, pattern, prime);
if (result != -1)
{
Console.WriteLine($"Pattern found at index {result}");
}
else
{
Console.WriteLine("Pattern not found");
}
}
Step 2:主程式
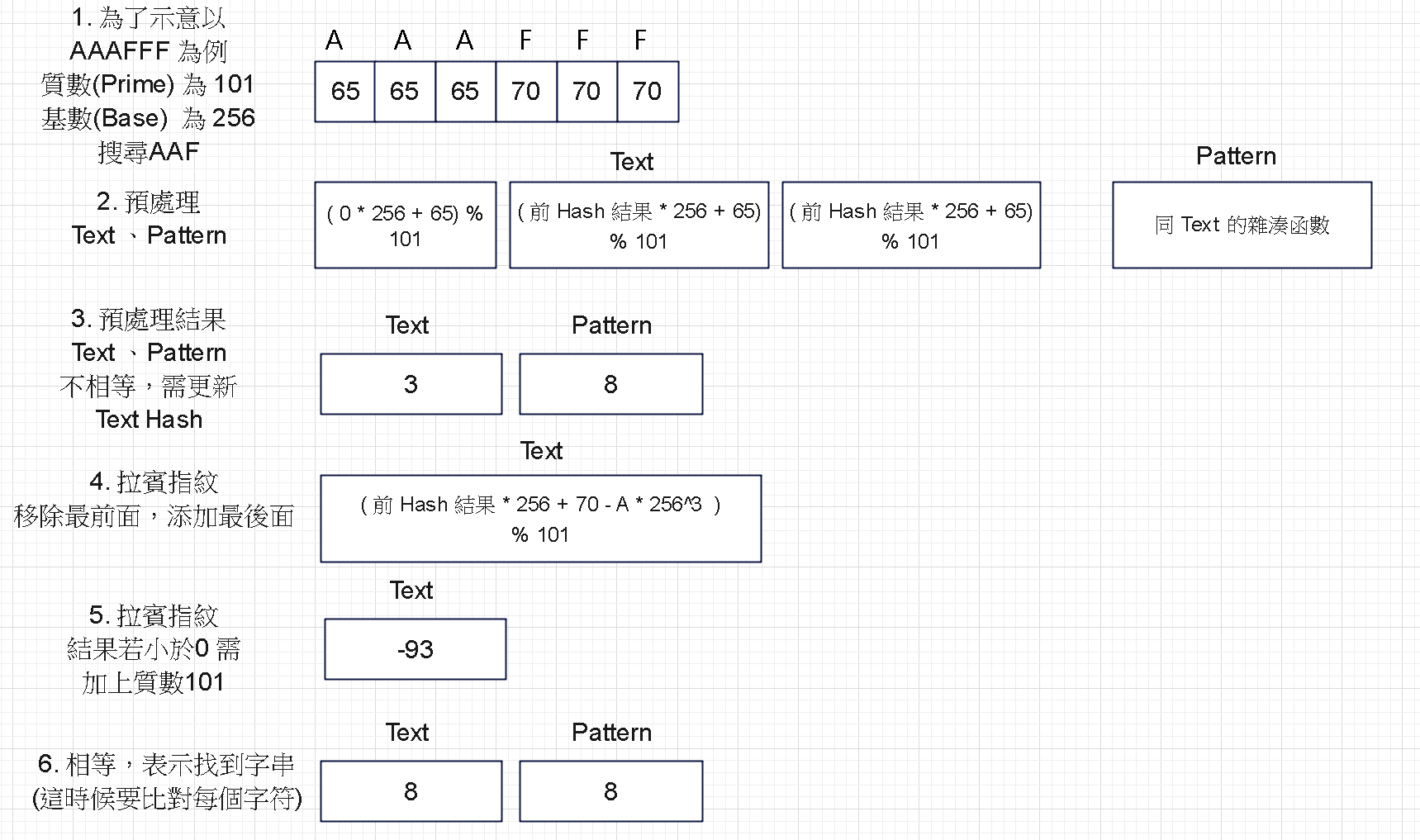
主程式包含了 5 大部分,每次沒有比對到後用 拉賓指紋 (Rabin Finger) 產生下一個哈希值,繼續比對。
其中 3-4. 是拉賓指紋的滑動窗口,計算下一字符的正確 Hash 方式
3-5. 因為取餘數(%)的方式,如果有小於0,加上開發者設定的質數 (Prime) 可使期到正確的 Hash 正數。
/// <summary>
/// 拉賓卡普搜索算法 - 拉賓指紋 (Rabin-Karp Algorithm)
/// </summary>
/// <param name="text">原始資料</param>
/// <param name="pattern">查詢的字串</param>
/// <param name="prime">使用自定義的質數</param>
/// <returns></returns>
private int RabinKarpSearch(string text, string pattern, int prime)
{
// 1. 預處理:計算文字和查詢對象的 Hash
int textLength = text.Length;
int targetLength = pattern.Length;
int patternHash = CalculateRabinFingerprint(pattern, 0, targetLength, prime);
int textHash = CalculateRabinFingerprint(text, 0, targetLength, prime);
// 2. 滑動窗口處理 ※最多滑動 textLength - patternLength 次
for (int index = 0; index <= textLength - targetLength; index++)
{
// 3-1. 匹配,如果 Hash 相等,則進一步比較
if (patternHash == textHash)
{
int findeIndex;
// 3-2. 進一步比較,比對字元是否相等
for (findeIndex = 0; findeIndex < targetLength; findeIndex++)
{
if (text[index + findeIndex] != pattern[findeIndex])
break;
}
if (findeIndex == targetLength)
return index;
}
// 3-3. 不匹配,更新 Hash 值
if (index < textLength - targetLength)
{
// 3-4. 更新文本窗口的哈希值
// ※ 舊Hash * 基數(這裡256) + 新字符 - 舊字符 * [基數(256)的目標字串長度平方]
// ※ Base 一定要選擇當前字符串大的值,例如 A-Z 共 26個字母,建議32或64,避免 Hash 碰撞
// ※ 此外 Base 愈小效能愈佳,但以現代電腦來說,差異不大
textHash = (textHash * 256 +
text[index + targetLength] -
text[index] * (int)Math.Pow(256, targetLength)
) % prime;
// 3-5. 負數轉正
if (textHash < 0)
textHash = (textHash + prime);
}
}
// 5. 沒找到,返回 -1
return -1;
}
Step 3:子函數 - 拉賓指紋
在預處理時會將搜尋目標、文本的前幾個字串(基於搜尋目標長度),透過拉賓指紋取餘的方式產生初始哈希值
/// <summary>
/// 計算拉賓指紋
/// </summary>
/// <param name="str">傳入的字串</param>
/// <param name="start">起始索引</param>
/// <param name="length">總長度</param>
/// <param name="prime">質數</param>
/// <return></return>
private int CalculateRabinFingerprint(string str, int start, int length, int prime)
{
int hash = 0;
for (int index = start; index < start + length; index++)
{
// 使用合適的質數取餘數
hash = (hash * 256 + str[index]) % prime;
}
return hash;
}
第五部分:拉賓指紋 - 圖解說明
Step 1:圖解說明